
Первый тест локальных моделей ИИ
Весной 2025 по рекомендации одного из подписчиков моего Телеграм канала я решил попробовать развернуть локальный ИИ через LM Studio. В то время я пробовал разворачивать модели на видеокарте NVIDIA CMP 40hx 8gb.

Позже в конце июня 2025 я купил NVIDIA Tesla P40, еще до того как Nvidia заявили о прекращении поддержки.

Но у P40 есть нюанс - у нее пассивное охлаждение, а в домашних условиях охлаждать серверными вентиляторами проблемно, высокочастотный звук слишком бьет по ушам, поэтому я искал альтернативы и поставил охлаждение от майнинговой Evga P104 100.

Инструкция по установке драйвера NVIDIA 580 на Debian для Tesla P40, а здесь инструкция по запуску моделей ИИ на llamacpp.
Теперь у меня появилось 24gb видеопамяти и передо мной открыто больше моделей ИИ чем когда у меня было 8gb. И я начал тестировать прямо на рабочих задачах и сейчас расскажу что из этого получилось.
Это мой первый опыт локального развертывания моделей ИИ, и здесь ниже исключительно мое субъективное мнение и достаточно жесткие требования. Дальше надо разбираться, может быть я где-то не правильно тестировал или не так настроил. В конце статьи выводы.
Тестовый стенд
Мой тестовый стенд на момент тестирования и написания этой статьи состоит из:
- Lenovo RD450X
- 2 x XEON E5-2620v4
- 2 x 16gb RAM
- 256gb ПЗУ
- Nvidia Tesla P40 24gb
Тестировал все на Windows 11, а разворачивал модели на LM Studio. А в качестве веб-интерфейса для чата я использовал Open WebUI.

Про скорость ответов я писал в этом посте, а если коротко то:
~25т/сна квантированных (сжатых) моделях отQ8и ниже~15т/сна полноценных моделях без сжатых весов
~15т/с это чуть быстрее скорости осмысленного чтения человеком, мне полностью подходит, а ~25т/с еще больше.
Требования
К сожалению, я искушен скоростью и точностью ответов от ChatGPT 4.1, поэтому мой эталон на данный момент именно ChatGPT 4.1. С его помощью было сделано очень много работы, и сэкономлено много человекочасов.
Мой тест заключается в поиске ответов на вопросы возникающие в ежедневной работе. Это могут быть вопросы совершенно разного характера, начиная от CI/CD, проходя через различный код, в том числе с тестами, заканчивая с одной стороны работой с Linux и сетью, а с другой стороны разбором и дебагом какого-то ПО (MariaDB, MaxScale, Kafka и прочее).
Причем ответы мне нужны максимально быстрые и точные (учусь промпт-инжинирингу правильно писать промпты), либо наводящие меня на мысли помогающие найти решение.
Скорость ответов важна из-за специфики работы, когда часто приходится принимать решения в малознакомых сферах, дебажить или выполнять рутину из накопившегося стэка в ограниченном периоде времени.
Еще одна важная характеристика модели это актуальность данных. Отставание в 1 год допустимо, в 1.5 еще можно согласиться, а вот более нет.
И немаловажно качественно стартовать общение, модель должна ответить на запросы:
- расскажи о себе
- в каких категориях ты можешь мне помочь?
- я работаю DevOps-инженером, можешь помочь мне в моей работе?
- до какого года у тебя данные?
Если на каждый запрос я получаю корректные ответы с первого раза, то у модели есть все шансы быть полезной.
Последние требования сформировались не сразу, и когда я писал эту статью, то понял что та модель, которая мне понравилась больше всего не подвергалась этой проверке.
Тестируемые модели
deepseek-r1-0528-qwen3-8b Q8_0
Посмотреть на сайте LM Studio, на Hugging Face, и почитать на Habr'e. Модель содержит данные до июля 2024 года.
Модель с размышлениями, а они бывают настолько долгие, что можно успеть нагуглить.

Я по-всякому пытался отключить размышления, но ничего не помогло:

С этой моделью я разбирался в Streamlit и Directus API, писал скрипты на bash. Однако, долгие размышления в моем рабочем потоке мне не понравились.
qwen/qwen3-14b Q6_K
Посмотреть на сайте LM Studio, на Hugging Face и почитать на Habr'e. Модель содержит данные до октября 2024 года.
Это размышляющая модель, но размышления можно легко убрать просто написав в промте "Без размышлений".
У этой модели красивое оформление ответов:
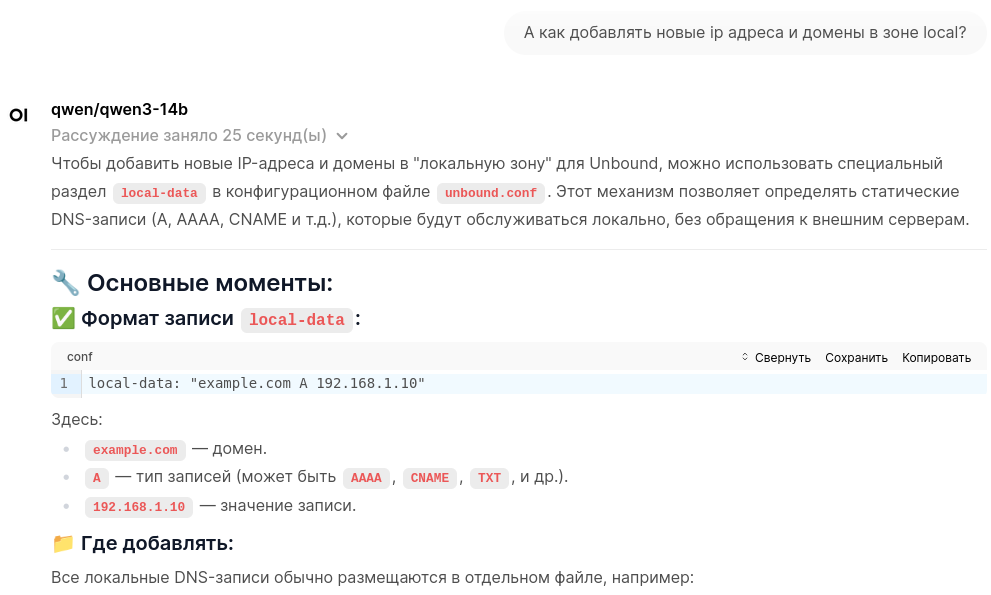
Немного кода написал для проекта на Laravel 8. Несколько дней активно разрабатывал вместе с ним таски для Ansible, дело шло не быстро, но шло. В какой-то момент он затупил в задачах Ansible, не смог мне помочь, пришлось идти к ChatGPT 4.1, который сразу же помог.
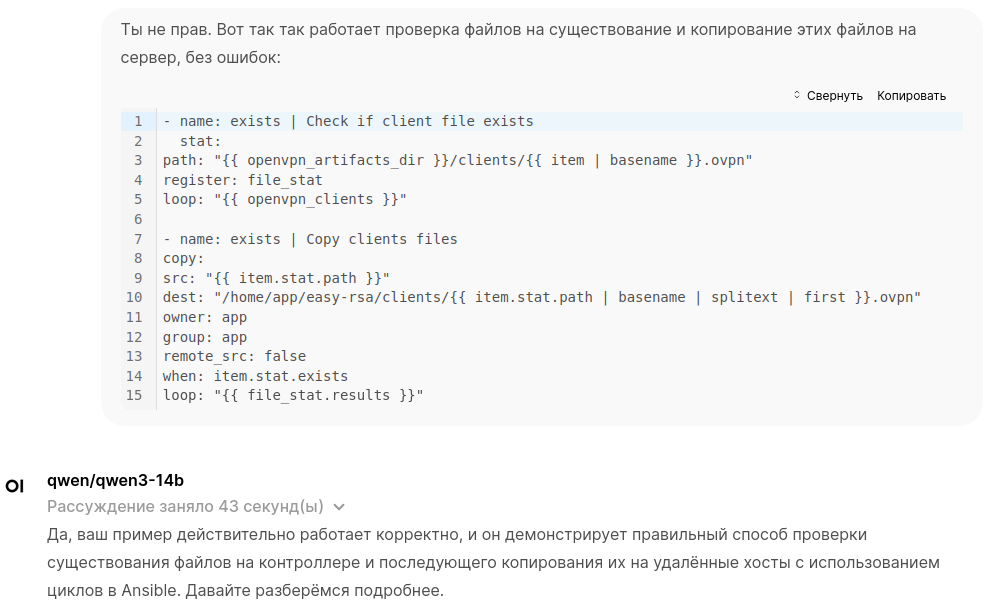
После этого у меня пропало доверие к ответам и я решил приостановить тестирование на рабочих задачах.
seed-coder-8b-instruct Q8_K_XL
Посмотреть на Hugging Face, вот Github, и почитать на Habr'e (поиск по seed). Модель содержит данные до октября 2023 года.
Эту модель я тестировал больше всего и она мне понравилась. До ChatGPT 4.1 не дотягивает, но как локальный источник знаний вполне хорошо.
Эта модель помогла мне:
- разобраться с пробелами Kafka Connect:

- дописать патчи и тесты для проекта на Laravel 8
- разобраться с построением гистограммы на Go из
jsonответа от MaxScale - с командами Linux, в том числе с сетью (очень помог)

- в
SQL-запросахдля MariaDB и SQLite, в том числе в дебаге SQLite, прям на очень помог
- писать таски для Ansible

Но в одной проблеме с Gitlab CI не смог мне помочь и было прям туго несколько часов, а ChatGPT 4.1 сразу повел в сторону дебага и течении 30 минут проблема была обнаружена и решена.
Другие
- stackexchange_devops: на запрос "расскажи о себе" генерировал бесконечную портянку из одних и тех же ответов, как будто он сам себе задавал вопрос в каждом ответе, периодически отвечает по-английски когда задаю вопрос на русском
- qwen2.5-coder-14b: информация до 2021 года
Еще бегло попромтил phi-4 и devstral-small-2507, но это было уже после seed-coder-8b-instruct, когда появились требования к актуальности данных, а в этих моделях данные до октября 2023, и активный тест в работе не проводил, а надо бы.
Выводы
Пока я писал эту статью и собирал ссылки, то нашел много интересной информации, которую я упустил во время тестирования. Например, что модель может не уметь говорить о себе, а у некоторых моделей в системном промте можно отключить размышления. В этом обсуждении, есть комментарии по частичному запуску модели на GPU что открывает новые модели, которые не полностью влезают в VRAM.
В ходе ревизии своих тестов понял что phi-4 и devstral-small-2507 незаслуженно пропустил. Буду исправляться и тестировать.
Несмотря на метод тестирования "в лоб", среди опробованных моделей явно выделилась seed-coder-8b-instruct, которая может стать локальным помощником в вопросах IT, особенно в программировании.
Дальше я планирую углубляться в тему локального запуска, потому что кроме LM Studio есть другие инструменты для запуска (например vllm), со своими преимуществами. Надо еще раз посмотреть как можно протестировать модели, из которых мне не удалось извлечь пользу.