
Fluentd как шина данных для HTTP сервисов
Fluentd - это open-source проект для унифицированного сбора и потребления данных. Звучит обобщенно, для лучшего понимания можно почитать архитектуру. А если кратко то: Fluentd потребляет данные из одного места и доставляет их в другое. Например, так можно доставлять логи из разных сервисов (Nginx, Syslog, из файла и прочее) в Elasticsearch.
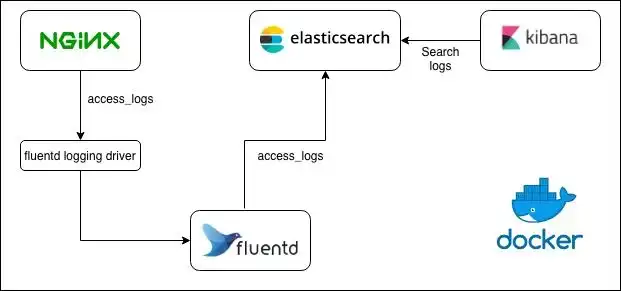
О том как пользоваться Fluentd можно почитать здесь.
Уже второй раз в моей практике встает вопрос об использовании Fluentd как шины данных между HTTP сервисами. Первый раз мы сделали доставку событий через Fluentd в Sentry и оно работает уже не первый год. А сейчас появилась задача, в которой есть 2 HTTP сервиса, один из них должен отправлять данные в другой, причем ассинхронно и с гарантией доставки.
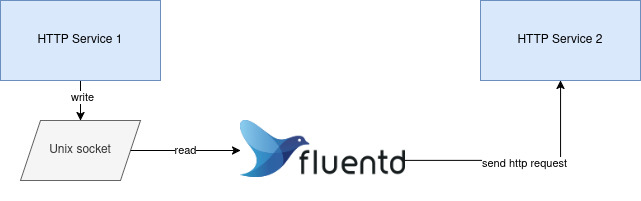
Наверняка возникает вопрос: а почему бы не использовать Kafka? Для этого нужно делать отдельный Consumer, и кажется что дешевле все-таки поставить между этими HTTP сервисами Fluentd, который доставит данные из одного сервиса в другой, отложено и по HTTP.
Я подготовил репозиторий с инструкцией, чтобы вы сами могли опробовать написанное в действии, внутри есть достаточное README, к тому же мы его рассмотрим в конце статьи для тестов. А сейчас пройдемся по основным настройкам во Fluentd.
Настройка приёма событий
Для начала нам нужно настроить прием событий во Fluentd, возьмем стандартный механизм forward, через этот механизм разные инстансы Fluentd пересылают друг другу сообщения:
<source>
@type forward
port 24224
bind 0.0.0.0
@log_level debug
</source>
Если мы работаем в среде контейнеров, например Docker, то мы работаем по сети, потому что в одном контейнере один основной процесс. Но если бы мы устанавливали Fluentd на хосте рядом с приложением, то удобнее было бы отправлять события из приложения через unix сокет.
Обработка событий
Теперь нам нужно настроить обработку полученных событий. В конфиге для обнаружения событий используется директива match, здесь мы указываем события с какими тегами мы хотим обнаруживать и обрабатывать. Например, нам нужны события только с тегом app:
<match app>
...
</match>
Или с вложенными тегами где первый app, а второй backend:
<match app>
...
</match>
Или нам нужны все вложенные события с тегом app до второго уровня:
<match app.*>
...
</match>
Или до третьего:
<match app.**>
...
</match>
И так далее.
Внутри match мы будем использовать http плагин для отправки этого события из Fluentd в наше HTTP приложение:
<match api.*>
@type http
@log_level debug
endpoint "http://http:8000/api/"
open_timeout 2
http_method post
content_type application/json
</match>
С таким конфигом Fluentd будет искать все события с тегом
apiи любым тегом на втором уровне вложенности и отправлятьPOSTзапрос на адресhttp://http:8000/api/сJSONв теле и таймаутом в 2 секунды.
Кажется что мы уже достигли цели, но это решение будет не полным без буферизации.
Буферизация
Буферизация во Fluentd используется для нескольких целей:
- Пакетная отправка: накопление данных перед отправкой в конечный сервис
- Гарантия доставки: повторная отправка, вплоть до того пока конечный сервис не примет данные
В нашем случае пакетная отправка не нужна (за один раз нам нужен 1 JSON, предположим что именно так работает наше API), и нас интересует только гарантия доставки.
События могут буферизироваться в ОЗУ (memory плагин) или в файл (file плагин), для надежности будем использовать файл.
После прочтения всех вышеперечисленных ссылок и документации по буферизации получается такой конфиг:
<match api.*>
@type http
@log_level debug
endpoint "http://http:8000/api/${tag[1]}/"
open_timeout 2
http_method post
content_type application/json
<buffer tag>
# буферизируем в файл ниже
@type file
path /fluentd/log/api.buffer
# отправляем до тех пор пока конечный сервис не примет события
retry_forever true
# отправляем сразу без накопления события в буфере
flush_mode immediate
# только 1 запись может быть в 1 буфере
chunk_limit_records 1
# максимальный размер всех буферов для данного match 10GB
# все остальные события после 10GB будут считаться утерянными
total_limit_size 10GB
# количество воркеров/потоков на отправку событий в HTTP сервис
flush_thread_count 10
# тип переотправки: увеличение паузы между попытками по экспоненте
retry_type exponential_backoff
# максимальная пауза между отправками 60 секунд
retry_max_interval 60s
# рандомизировать время отправки, чтобы у нас не было большого потока
retry_randomize true
# не сжимаем, храним только текст
compress text
</buffer>
</match>
Здесь есть некоторые изменения и дополнения по сравнению с предыдущим вариантом:
- теперь события отправляются на динамический эндпоинт
http://http:8000/api/${tag[1]}/, который формируется исходя из второго тега - секция с буферизацией настроена на буферизацию в файл с гарантией доставки
Рассмотрим нюансы:
retry_forever: по умолчаниюfalse, а это значит что когда-то сообщения с ошибкой доставки будут выброшены из Fluentd, например поretry_timeout, который по умолчанию 72 часа, поэтому мы ставимtrueчтобы сообщения с ошибкой доставки никогда не выкидывались из очередиflush_mode: выбранimmediateчтобы моментально отправить сообщение в приёмникchunk_limit_records: количество записей в одном чанке буфера (в одном файле) 1, иначе у нас в один чанк будет сложено несколькоJSONи весь этот чанк будет отправлен в нашеAPI, которое не ожидает такого
Пример
В приведенном репозитории есть контейнер с Fluentd, который настроен на прием событий (отправляет скрипт send.py) с тегом и переотправкой его в контейнер http по HTTP протоколу (server.py).
Поднимаем все контейнеры так:
docker compose up -d
И пробуем отправить событие во Fluentd из Python скрипта:
docker compose up app
В логах мы увидим успешную отправку:
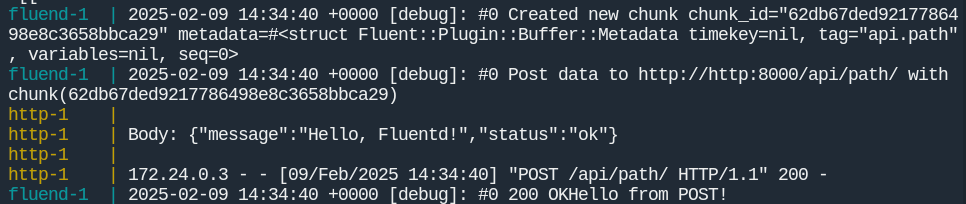
Для тестирования гарантированной доставки нужно:
- отключить контейнер
http:
docker compose stop http
- отправить сообщение во Fluentd:
docker compose up app
В логах можно увидеть сообщения о неудачной доставке, стоит обратить внимание на название чанка и дату следующей отправки события:

- включить контейнер
http:
docker compose start http
Теперь сообщение будет успешно доставлено до HTTP сервера в следующую дату доставки события (опять смотрим на название чанка):
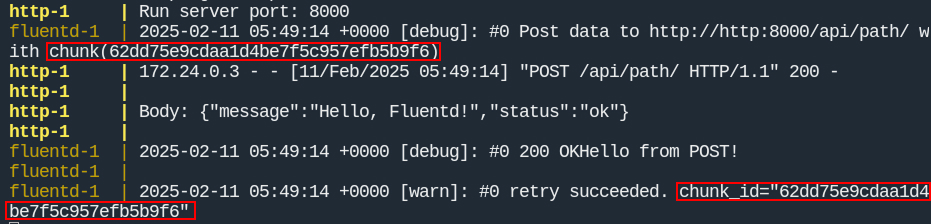
Выводы
Это вполне рабочее решение, которое мы уже второй год тестируем на Sentry, однако эта схема не чувствительна к потерям и задержкам. Привычные механизмы доставки бизнес-данных через Kafka или RabbitMQ кажутся более надежными или как минимум проверенными временем и множеством компаний. Надо дать время этой схеме проявить себя в продакшене)