
Остановка бесконечных запросов от Gitlab Registry
Случилась ситуация: в docker-реестре закончилось место на диске. С одной стороны ничего необычного можно просто расширить место, но если посмотреть на график, то возникает вопрос "почему так резко?":
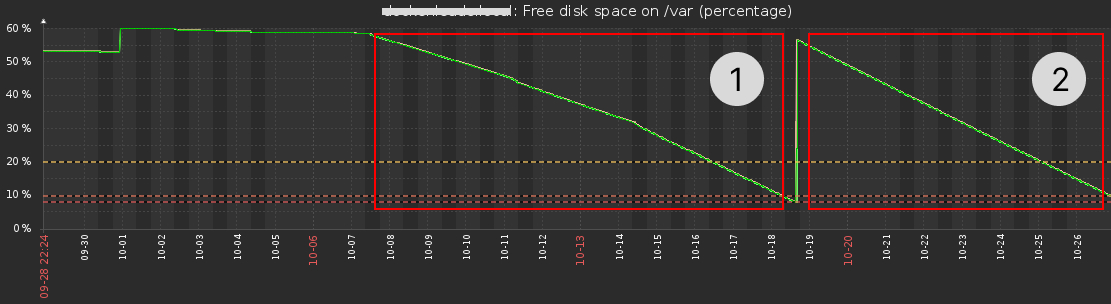
Временное решение
В начале выяснений было определено что это быстрорастущие логи docker-контейнера (/var/lib/docker/containers/*/*-log.json), очистить которые достаточно просто если уж совсем время поджимает. Так можно почистить все логи:
truncate -s 0 /var/lib/docker/containers/*/*-json.log
А для очистки конкретного файла лога можно:
echo '' > /var/lib/docker/containers/HASH/HASH-json.log
Чистить логи для решения проблемы может показаться неразумным решением, но порой на продакшене это имеет место быть. Например, когда мы уже знаем о проблеме, она не требует срочного решения, но сейчас нужно временное действие.
Откуда возникает проблема?
Если заглянуть в лог контейнера, то можно увидеть многочисленные записи вида:
{"log":"time=\"2024-10-27T06:25:51.852376136+03:00\" level-error msg=\"response completed with error\" auth.user.name= err.code=\"digest invalid\" err.message=\" provided digest did not match uploaded content\" go.version=go1.11.2 http.request.host=docker.domain.zone http.request.id=dd559f21-bc11-4104-900a-9214ccf9aeeb http. request.method=DELETE http.request.remoteaddr=\"172.18.0.74:56282\" http.request.uri=\"/v2/USER/REPO/manifests/latest\" http.request.useragent =\"GitLab/17.3.5\" http.response.contenttype=\"application/json; charset=utf-8\" http.response.duration=1.490791ms http.response.status=400 http.response.written =98 vars.name=\"USER/REPO\" vars.reference=latest \n", "stream":"stderr", "time": "2024-10-27T03:25:51.852435096Z"}
{"log":"172.18.0.74 [27/Oct/2024:06:25:51 +0300] \"DELETE /v2/USER/REPO/manifests/latest HTTP/1.1" 400 98 \"\"\"GitLab/17.3.5\"\n", "stream":"stdout","time":"2024-10-27T03:25:51.852512342Z"}
Здесь явно говориться про ошибку удаления образа из реестра: Gitlab пытается удалить, а реестр отвечает ошибкой, и так бесконечность.
Gitlab это делает через воркеры, информацию по которым можно узнать перейдя в веб-интерфейсе Admin area - Monitoring - Background jobs:

Как выяснилось позже, проблема возникает при попытке удалить образ через веб-интерфейс Gitlab, выявление проблемного звена в этой цепочке это отдельная история, а что делать сейчас?
Прервать этот цикл штатными средствами через API не получилось, ведь Gitlab сам пытается через API удалить образ. Однако, как-то надо разрешить эту ситуацию, вручную чистить логи при каждом триггере не лучший вариант.
Решение
Немного углубившись в размышления можно предположить: воркеры отправляют запросы и ожидают вменяемые ответы успеха, или как минимум код ответа сигнализирующий об успешном удалении образа. Иного объяснения мне не удалось найти, поэтому я стал копать в эту сторону, надо пробовать как-то решать проблему.
Решение не элегантное, но сейчас нужно как-то остановить эту вакханалию, а потом разбираться где корень проблемы,
потом разбираться конечно же никто не стал, потмоу что проблема случается дважды в год.
Для реализации я взял docker-образ Nginx с таким конфигом app.conf:
server {
listen 80;
server_name _;
location / {
return 301 https://$host$request_uri;
}
}
server {
listen 443 ssl;
server_name _;
ssl_certificate /etc/nginx/ssl/docker-registry.crt;
ssl_certificate_key /etc/nginx/ssl/docker-registry.key;
location / {
return 200;
}
}
Все стандартно: редирект на https и конфиг для https. Однако, на любой запрос по https будет ответ 200.
Прикрепляю docker-compose.yml, чтобы не выдумывать команду запуска:
services:
webserver:
image: nginx:1.21.6
restart: always
ports:
- '80:80'
- '443:443'
volumes:
- ./app.conf:/etc/nginx/conf.d/default.conf
- /var/opt/docker/registry/certs/:/etc/nginx/ssl/
Запускаем и смотрим:
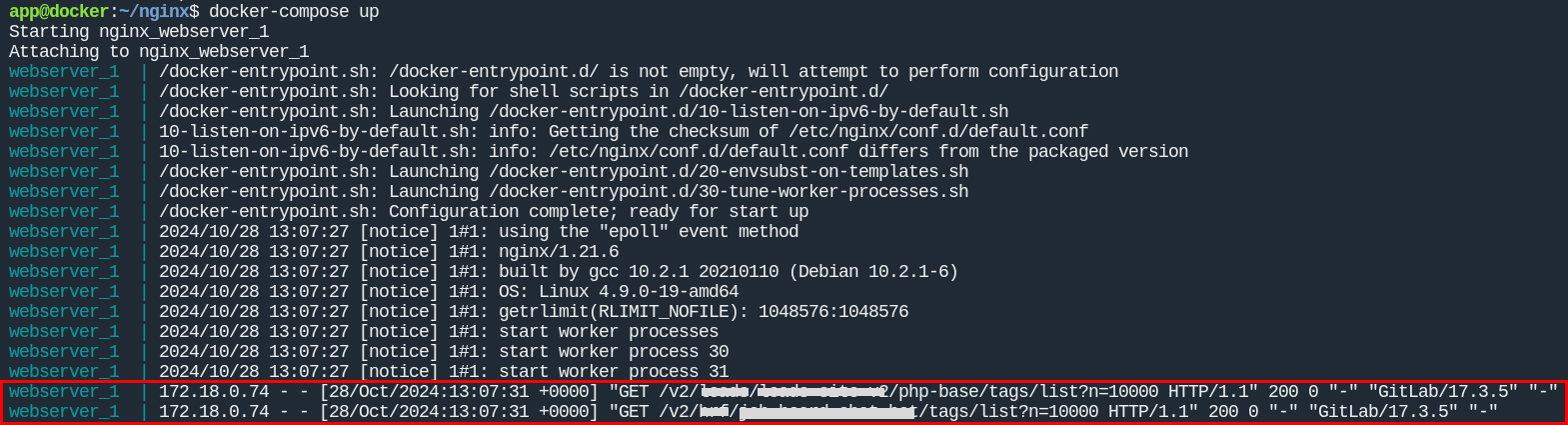
Как и предполагалось
Gitlab Registryотправляет 2 запроса на удаление образов вDocker Registry, они получают успешный код ответа (200) и на этом успокаиваются)