
Запуск локальных модели ИИ через llama.cpp
В прошлый раз мы установили драйвера для видеокарт NVIDIA на Debian 12 580 версии, чтобы все возможные/подходящие видеокарты для инференса поддерживались, а в этот раз быстро и просто запустим сервер llama.cpp в Docker, получим API и готовый веб-интерфейс для чатов с моделью ИИ.
Docker образы
В документации llama.cpp есть разные контейнеры для запуска моделей, а разные потому что зависят от комплектации контейнера и ваших мощностей. Если вам нужен только сервер, то нужно качать контейнер с тегом server, а если у вас видеокарты от NVIDIA, то нужен контейнер с тегом cuda.
Выше как раз описан мой вариант, поэтому я скачиваю образ так:
docker pull ghcr.io/ggml-org/llama.cpp:server-cuda
Скачивание моделей
У сервера есть различные опции для запуска модели, посмотреть их можно в документации, а для начала мы скачаем какую-нибудь модель ИИ для запуска через llama.cpp, например gpt-oss-20b.
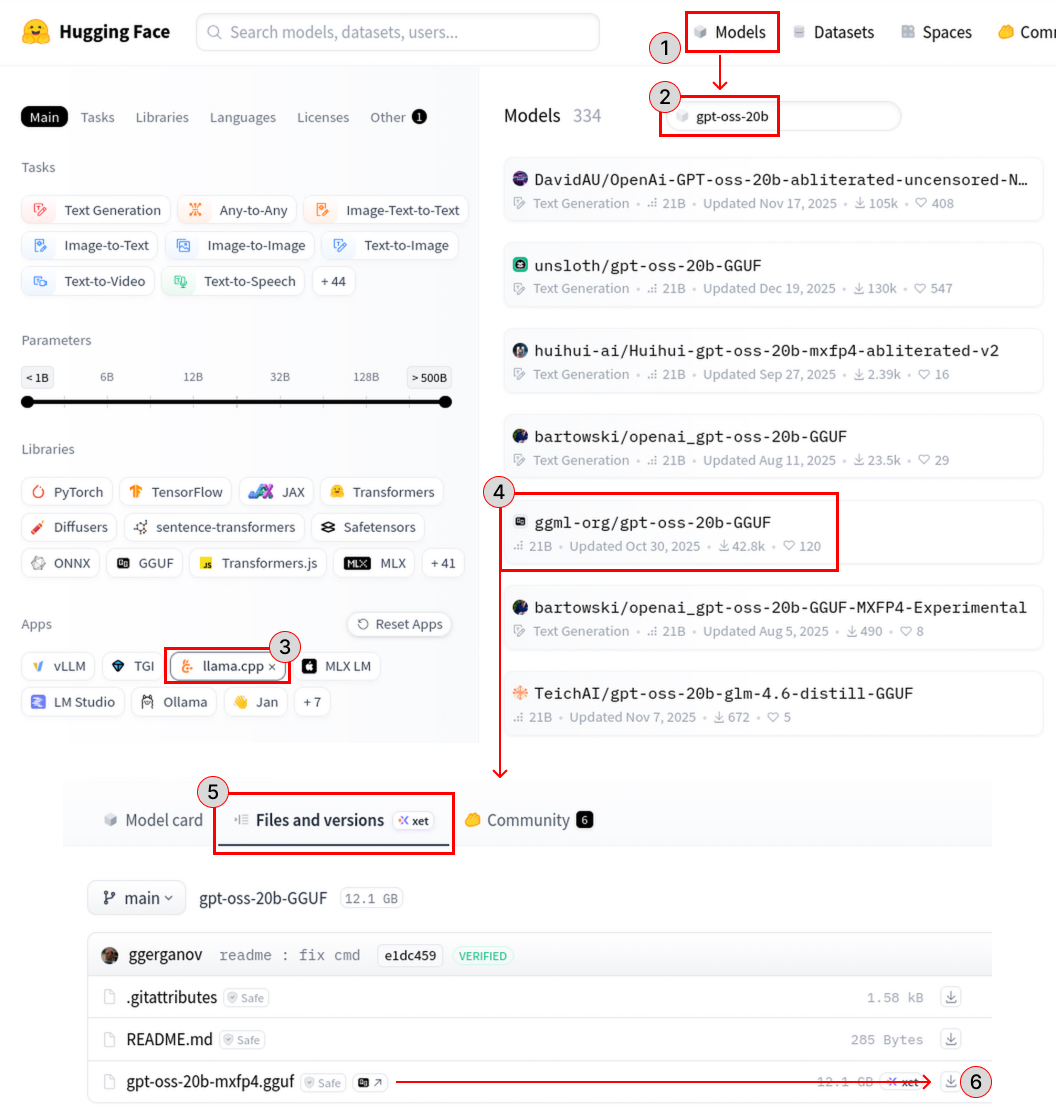
wget https://huggingface.co/ggml-org/gpt-oss-20b-GGUF/resolve/main/gpt-oss-20b-mxfp4.gguf
Запуск сервера
В текущей директории создадим директорию llamacpp/models и переместим сюда наши модели, дальше мы будем прокидывать эту директорию в контейнер.
Для выполнения следующей команды необходимо установить драйвера NVIDIA и настроить рантайм Docker контейнеров, если вы этого еще не сделали то пройдите по ссылке на инструкцию.
docker run \
--gpus all \
-d \
-p 8000:8000 \
-v "$PWD/llamacpp/models/:/models" \
ghcr.io/ggml-org/llama.cpp:server-cuda \
-m /models/gpt-oss-20b-mxfp4.gguf \
--host 0.0.0.0 --port 8000
Здесь:
--gpus allпрокидываем все видеокарты в контейнер-dзапускаем в фоне-p 8000:8000прокидываем порт8000из контейнера на хост, именно на этом порту мы будем запускать сервер-v "$PWD/llamacpp/models/:/models"все наши модели будут храниться внутри контейнера по пути/modelsghcr.io/ggml-org/llama.cpp:server-cudaуказываем недавно скачанный образ-m /models/gpt-oss-20b-mxfp4.ggufпуть к файлу модели--host 0.0.0.0 --port 8000запускаем сервер на всех сетевых интерфейсах на порту8000
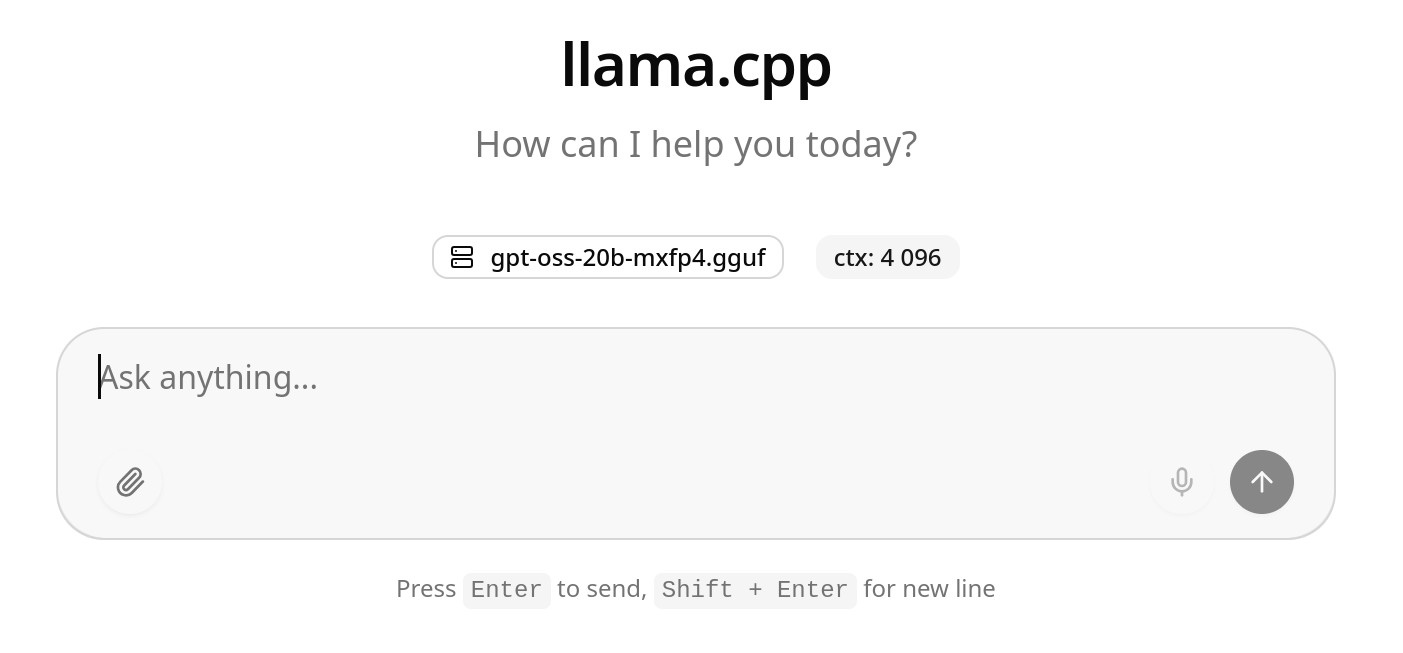
Уже сейчас можно идти в браузер запускать веб-интерфейс на http://127.0.0.1:8000 и радоваться или разочаровываться локальному инфересу.
А теперь рассмотрим нюансы.
Управление контекстом

Сразу бросается в глаза маленький контекст. Изменить это дело можно при помощи опции -c или --ctx-size с последующим указание размера контекста в количестве токенов. Например: -c 131072.
Параллельные чаты
По умолчанию будет доступен 1 чат, а все остальные запросы будут ждать в очереди, но можно их распараллеливать при помощи опции -np указав желаемое количество одновременных чатов.
Контекст между одновременными чатами делится на всех равномерно. Если контекст был 128к и 4 одновременных чата, но каждому из чатов будет доступно только 128к / 4 = 32к.
Также стоит отметить что производительность при одновременных чатах проседает, нелинейно, но ощутимо. Здесь в телеграм-канале я писал об этом подробнее.
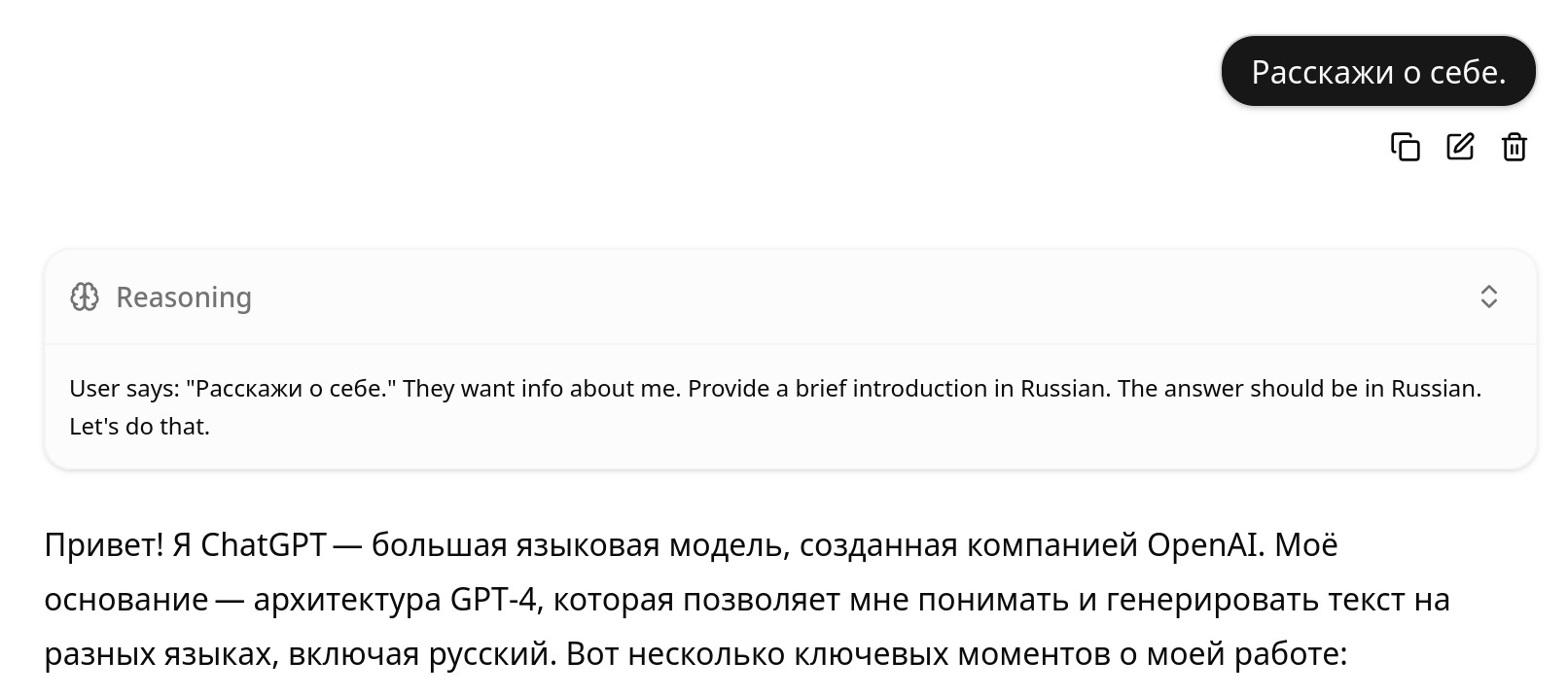
Формат размышлений
Через стандартный веб-интерфейс llama.cpp или через OpenWebUI размышления выводятся в странном формате:

Чтобы это сделать более юзабельным и скрыть в спойлер можно использовать набор опций --jinja --reasoning-format auto, теперь все будет более привычно:
Управление загрузкой слоев модели
А куда загрузилась модель: в RAM или GPU? Чтобы не гадать можно явно указать сколько слоев грузить на видеокарты, например так: --n-gpu-layers 99. Но тогда возникает вопрос, а как узнать сколько слоев в модели? При загрузке модели в логе можно увидеть print_info: n_layer = 36. Или можно поставить большое число чтобы точно все пошло на видеокарту.
Более радикальный способ указать загрузку всего только на GPU это использовать опцию --no-host - запрет выделения памяти на CPU, только в GPU.
Использование опции
--no-hostможет привести к ошибкамout of memoryесли модель не влезает в видеокарту полностью.
Оптимизация для MoE
А если вы загружаете MoE-модель (например gpt-oss-*20b) и у вас недостаточно видеопамяти для размещения ее целиком в видеопамяти, то можно воспользоваться некоторой оптимизацией - загрузить слои маршрутизации на GPU, а экспертные слои на CPU вот так:
-ngl 99указываем что хотим все загрузить вGPU-cmoeздесь говорим что загружаем слои маршрутизации наGPU(полностью), а экспертные слои наCPU
Разделить модель на несколько видеокарт
В опции -m указываем имя модели, а если у вас несколько файлов модели, то, как правило, они связаны между собой в имени модели, поэтому указываем только первое из них, а остальные llama.cpp подтянет самостоятельно.
По умолчанию llama.cpp самостоятельно разделит модель между видеокартами, но можно вмешаться в этот процесс при помощи опций:
--split-mode layerрежим разделения модели по слоям--tensor-split 0.5,0.5разделить на 2 видеокарты по 50%
Если решите вмешаться в разделение слоев между видеокартами, то посмотрите на опции
--fit, они позволяют выравнивать память.
Название модели
Чтобы сделать желаемое для глаза имя, можно использовать опцию --alias gpt-oss:20b.
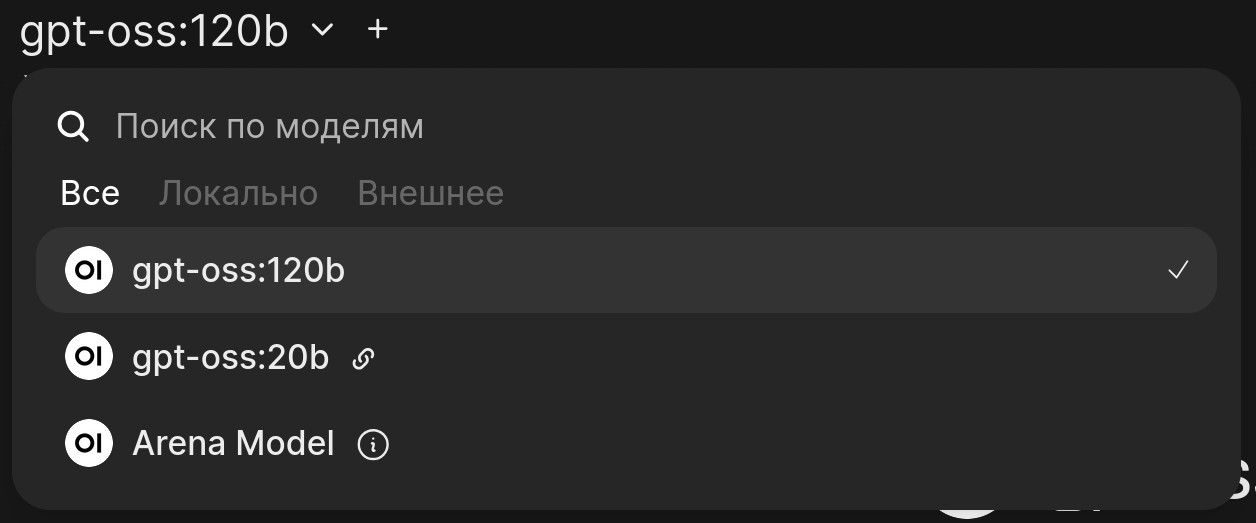
Сработало для
OpenWebUI, но не работает для штатного веб-интерфейсаllama.cpp.
Метрики
При помощи опции --metrics по адресу http://localhost:8000/metrics можно получить вывод метрик в формате prometheus и в последующем визуализировать их в Grafana, например так:
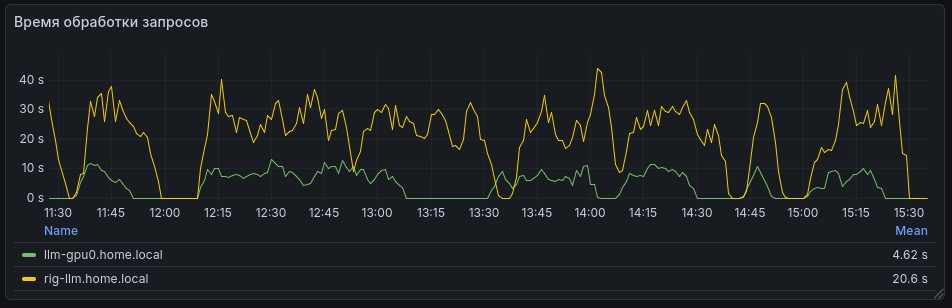
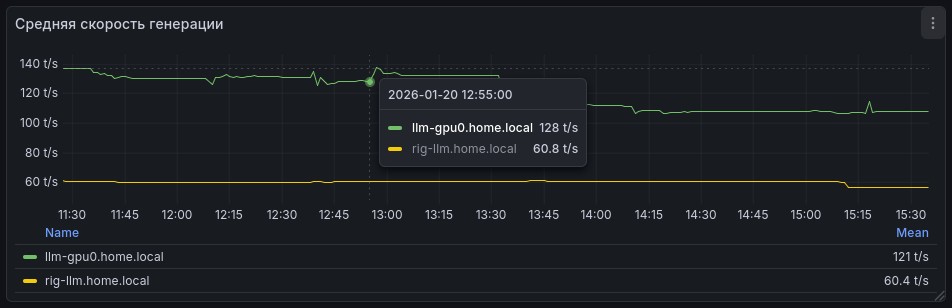
Авторизация
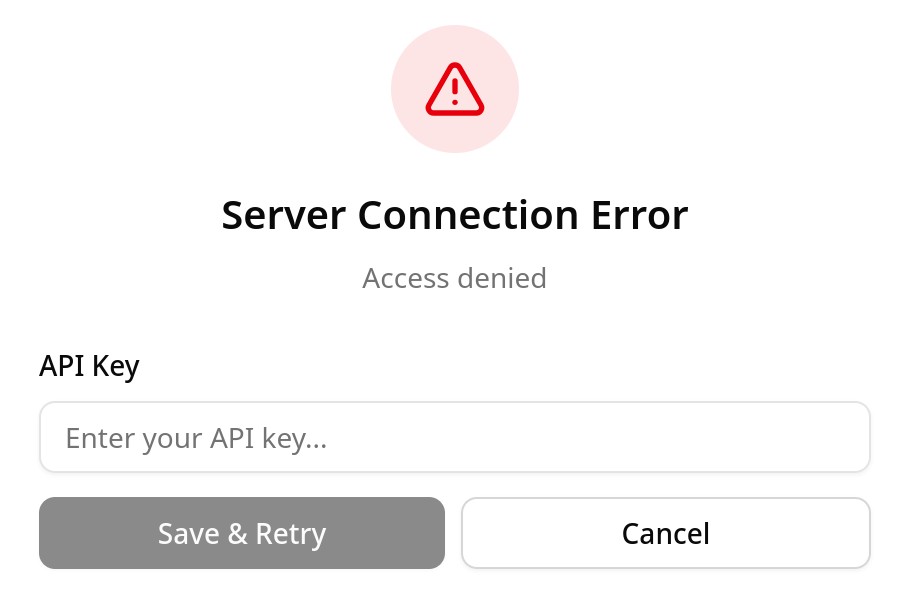
По умолчанию API и веб-интерфейс доступны без авторизации, но ее можно настроить через опцию --api-key с указанием произвольной строки/токена. Теперь этот токен можно ввести в веб-интерфейс или отправить в запросе API в заголовке Authorization: Bearer <токен>:
docker-compose.yml для запуска llama.cpp
Привожу свой docker-compose.yml для запуска модели gpt-oss-20b:
services:
llama_cpp_server:
image: ghcr.io/ggml-org/llama.cpp:server-cuda
container_name: llama_cpp_server
restart: always
ports:
- "8000:8000"
volumes:
- ./models:/models
deploy:
resources:
reservations:
devices:
- driver: "nvidia"
count: "all"
capabilities: ["gpu"]
# device_ids: ["1"]
command: >
-m /models/gpt-oss-20b-mxfp4.gguf
--alias gpt-oss:20b
--host 0.0.0.0
--port 8000
--ctx-size 131072
-np 1
--n-gpu-layers 99
--metrics
--jinja
--reasoning-format auto
-fa on
Здесь есть закомментированная строка device_ids: ["1"], она позволяет прокидывать в контейнер только определенные видеокарты (нужно закомментировать count: "all") по индексам как в nvidia-smi:
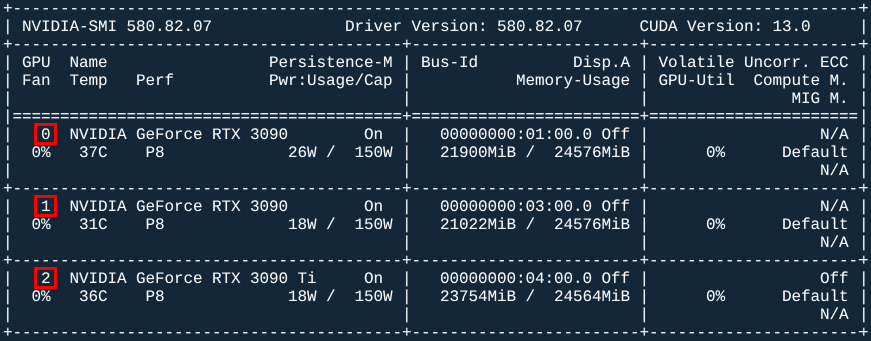
Такой конфиг, только для gpt-oss-120b, запущен на моем домашнем AI-сервере:
