Устраняем заполнение диска Sentry
В середине 2023 года мы успешно запустили Sentry self-hosted на нашем сервере с выделенными 40гб диска. Примерно через год я написал 2 статьи про Sentry: установка и настройка и внедрение в разработку.
С тех пор к нам в Sentry пришло много багов, большая часть из них была исправлена, проектов заводилось все больше и больше, а диск разрастался.
Проблема
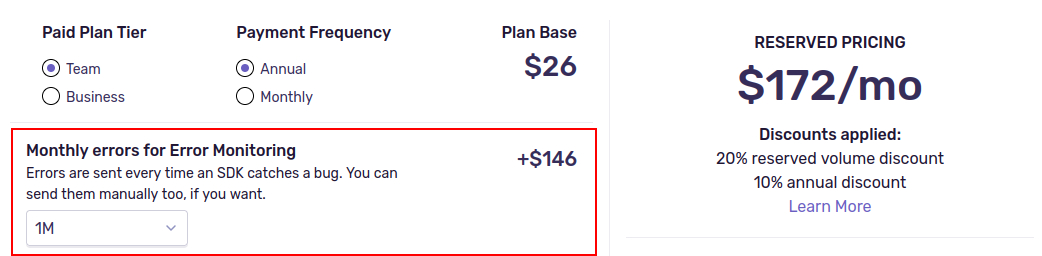
На 3-х месячном графике ниже выделены зоны, где было увеличение диска (от 5 до 20гб за раз):
Диска каждый раз не хватает, иногда он полностью заполняется и нам приходится расширять его снова и снова. Теперь объем диска 130гб. Так будет происходить постоянно если мы ничего не предпримем ...
Причина
Все дело в подобного рода ошибках:
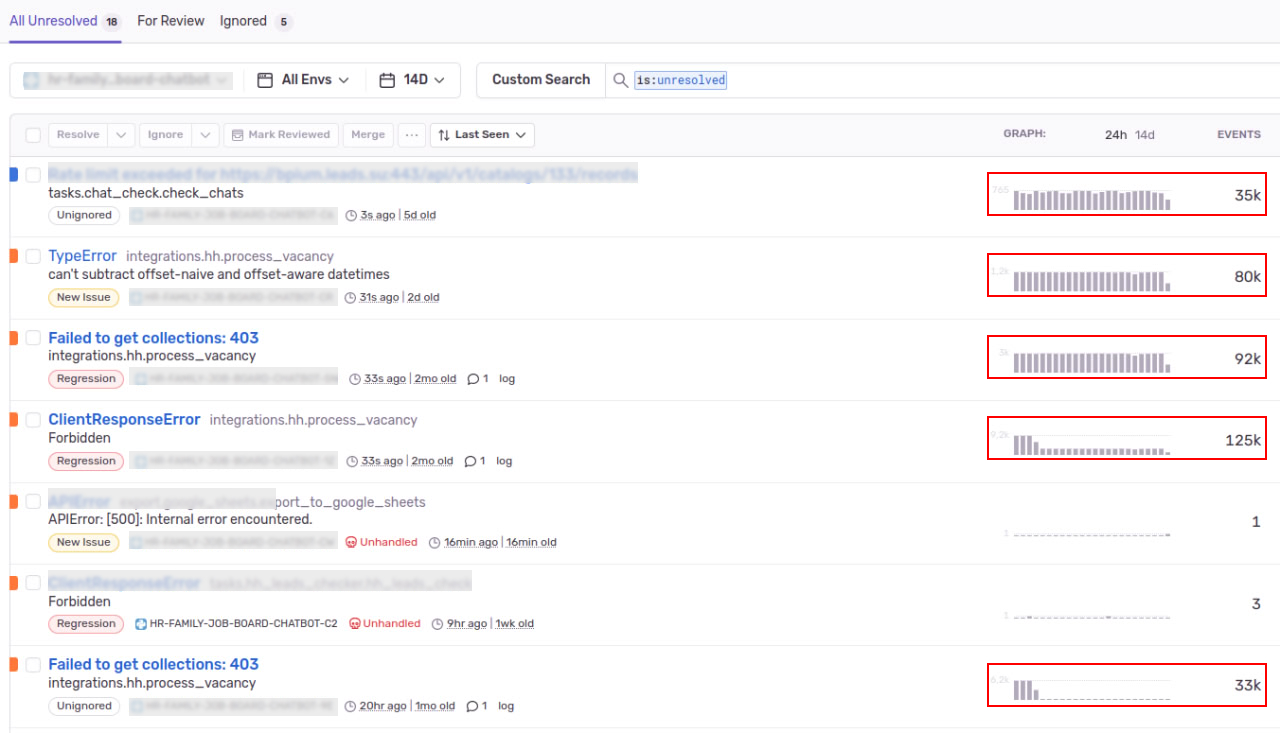
Событий за период по таким ошибкам слишком много. Что это? Реальная ошибка недополученной ценности клиентом или какое-то внутреннее нарушение реализации функции? На самом деле каждый случай индивидуален:
- Веб-интерфейс: где-то в веб-интерфейсе есть критичный баг и клиент это видит
- Фоновый процесс: где-то он не может достучаться до внутреннего сервиса причем многопотчоно и делает это бесконечное количество раз
- Логи как ошибки: где-то разработчики размышляют про ошибки как про логи "пусть будет информация, потом что-нибудь придумаем", и успешно игнорируют, а данные по issue поступают
И как быть?
На стороне клиента можно настроить sample rate, но клиентов много, везде нужно договориться, сделать и протестировать. А что делать если это сейчас не уместить в спринт? Дальше расширять диск?
Здравый смысл подсказывает что нужно системно работать над устранением ошибок, но скажите это продактам и разработчикам проблему нужно решить здесь и сейчас, потому что именно сейчас диск почти забит!
Решение 1 - Ограничение
У каждого проекта есть DSN, и каждый DSN можно конфигурировать:
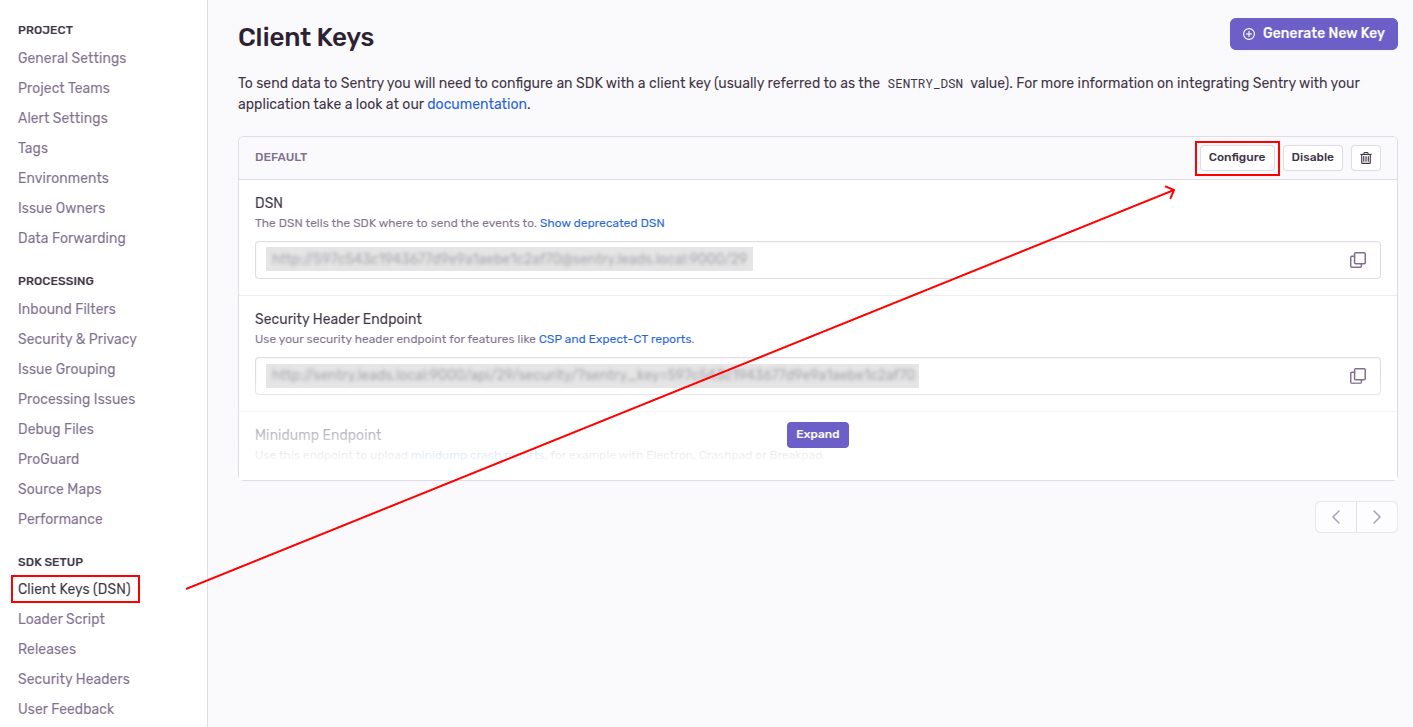
А точнее можно настроить лимиты входящих запросов:
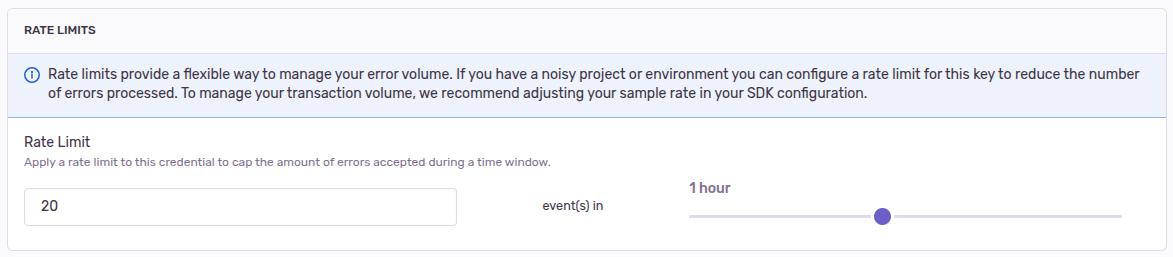
На скрине выше выставлен лимит в 20 событий за 1 час, а все остальные запросы будут отклонены. Вот так график входящих запросов будет выглядеть после настройки:
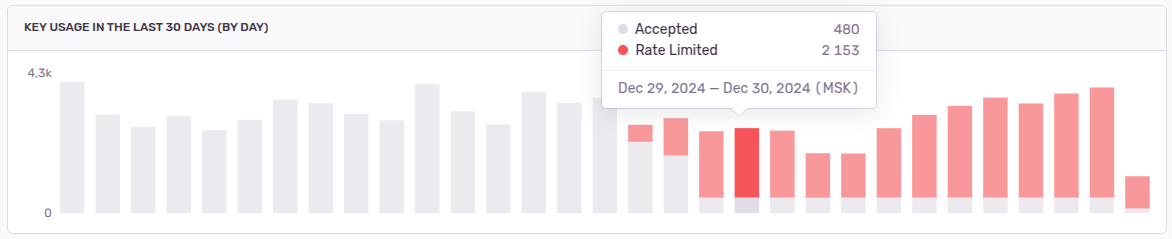
Таким образом мы остановили бесконечный поток событий по ошибкам из наших приложений в Sentry, можем немного расширить диск и спокойно пережить выходные :)
Решение 2 - Очистка
Предыдущее решение позволило остановить поток данных и интенсивное потребление диска, теперь этого меньше, но оно есть и спустя некоторое время мы опять увидим что диск на сервере Sentry заполнен.
В Sentry не работает очистка от старых данных?
У нас стоит очистка данных старше 90 дней, и те issue по которым нет событий больше 90 дней удаляются. Но что-то здесь не так.
Возьмем накопительную диаграмму по всем проектам за период (Stats в сайдбаре):
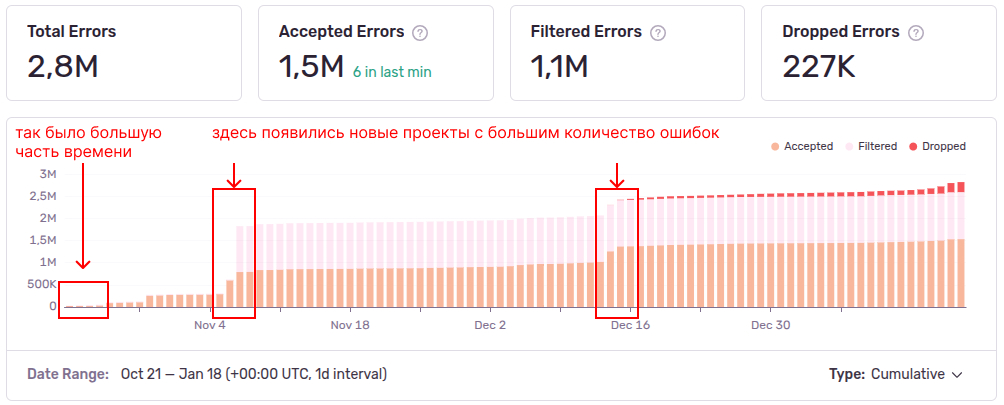
Это говорит нам о том, что на конец периода, у нас на диске хранится информация про 1 529 905 событий и по каждому: стектрейс, теги, список пакетов и множество другой мета информации:
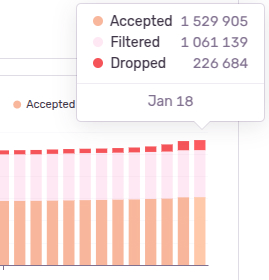
Когда-то у нас было мало данных и мы умещались в ресурсы сервера, а теперь данных стало очень много, точнее внезапно стало много.
Запустить очистку вручную
Можно попробовать выполнить sentry cleanup зайдя в контейнер:
# вход в контейнер
$ docker exec -it sentry-self-hosted-worker-1 bash
# справка по очистке sentry
$ sentry cleanup --help
# пример команды очистки всех событий старше 15 дней
# sentry cleanup --days 15
Но в моем случае это не дало результата и я начал свое расследование.
Кто съедает диск?
Еще немного поискав в интернете можно найти в чем суть проблемы - это таблица nodestore_node в postgres, которая хранит необработанные данные по каждому событию. Но мы проверим так ли это на самом деле.
Логинимся под пользователем postgres и входим в консоль Postgres:
# вход в контейнер с Postgres
$ docker exec -it sentry-self-hosted-postgres-1 bash
# логинимся под пользователем postgres
$ sudo -i -u postgres
# вход в консоль Postgres
$ psql
Выводим список баз данных с размером при помощи команды \l+:

Список таблиц с размерами:
SELECT
table_name,
pg_size_pretty(pg_total_relation_size(table_name::text)) AS "Size"
FROM
information_schema.tables
WHERE
table_schema = 'public'
ORDER BY
pg_total_relation_size(table_name::text) DESC;
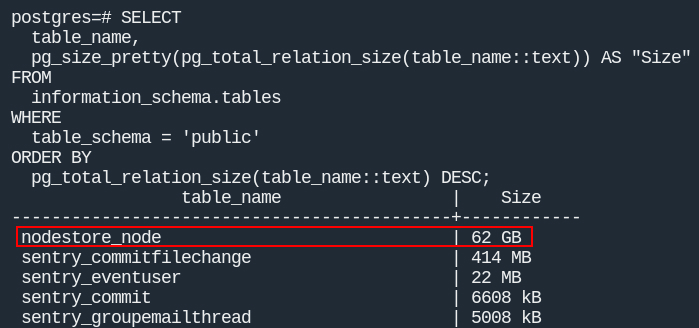
Смотрим сколько там строк:

Теперь исходя из этого обсуждения попробуем удалить данные старше 90 и 60 дней:
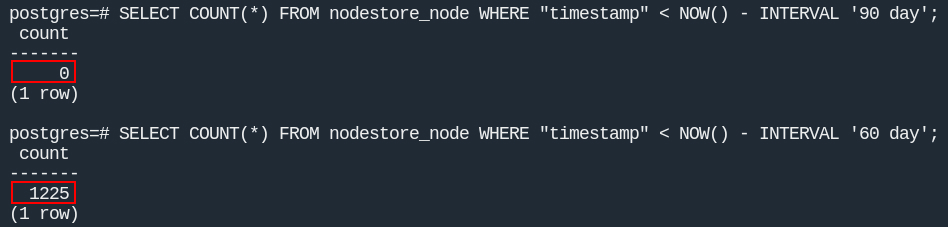
64гб занимает СУБД Postgres, таблица
nodestore_node62гб (10 632 432записей), причем данных старше 90 дней нет, а старше 60 дней всего лишь1225(0.01%). То есть все очистки, которые применяются внутри контейнеров, работают, просто данные сосредоточены под конец периода.
Ручное удаление и освобождение диска
В итоге были удалены данные старше 14 дней (к сожалению скрина не осталось, но счет идет на миллионы записей):
DELETE FROM nodestore_node WHERE "timestamp" < NOW() - INTERVAL '14 day';
Однако, это еще не все, теперь нам нужно выполнить VACUUM FULL для перестройки таблицы и очистки неиспользуемых данных:
VACUUM FULL nodestore_node;
Эта операция полностью блокирует таблицу и требует дополнительного места на диске (в моем случае 23 гб), так как происходит копирование данных из старой таблицы в новую.
Таблица весила 63гб, стала 23.
Эту операцию нужно периодически производить вручную, исходя из этого обсуждения СУБД Postgres не является оптимальным вариантом и используется вендором для разработки и дистрибуции self-hosted.
Для выхода из консоли Postgres: \q.
Итог
Нам удалось не только остановиться объемный поток данных в Sentry, но и почистить диск от данных.
Под конец статьи у меня возник вопрос: а что там с облаком в Sentry? Не проще ли хоститься у вендора?
- Вендор ушел из России: на сайте Sentry и вот еще на vc
- Ошибки стоят денег: все ошибки сверх тарифа (50к ошибок в месяц) стоят дополнительных затрат, наверное, для компании не много, но все же (можно сказать что даже меньше чем оплата работы инженера, но если смотреть в перспективе то может быть совсем по другому):