
Как устроен Vinyl в Tarantool
- Что такое Vinyl?
- Файловая структура спейса на Vinyl
- Визуализация хранилища Vinyl
- Фоновые процессы
- Как работа Vinyl влияет на систему?
- Очистка дерева от старых версий и удаленных кортежей
В прошлый раз мы разбирали управление спейсами в Tarantool на уровне пользователя, теперь пойдем дальше и разберемся как работает движок Vinyl и как его обслуживать.
У Tarantool есть достаточно подробная и понятная документация по движку Vinyl. В этой статье я собрал краткую выжимку из документации и своего опыта траблшутинга Tarantool. Мы попытаемся разобраться в файловой системе и процессах обслуживания движка Vinyl, на практике посмотрим как это выглядит.
Что такое Vinyl?
В Tarantool есть 2 движка Memtx и Vinyl. Здесь в документации описаны различия. А если по простому то: Vinyl хранит данные на диске, а Memtx в ОЗУ.
Как правило, ОЗУ меньше чем диск по объему, но быстрее, поэтому на движке Vinyl можно хранить больший объем данных с меньшей скоростью доступа.
Одно из ключевых свойств движка Vinyl это версионность реализуемая на основании LSM-дерева:
Когда выполняется запрос в Tarantool операция сохраняется в
LSM-дереве, а выполняется уже только во время слияния (это называется компакция, поговорим о ней ниже). При этом предусмотрены различные механизмы проверок на ошибки, чтобы не допустить проблем при фоновом слиянии.
Однако, природа отложенности выполнения в Vinyl иногда способна создавать проблемы:

Судя по логу можно понять что во время создания контрольной точки был произведен сброс дампа на диск, но он завершился провалом, потому что один из кортежей не вмещался в vinyl_max_tuple_size, отсюда рост числа временных файлов .run.inprogress для попытки сбросить дамп.
Увеличение vinyl_max_tuple_size на текущей версии Tarantool не спасло. Помогло обновление Tarantool до новой версии + увеличение vinyl_max_tuple_size.
Представленная проблема встретилась на одном кластере Tarantool, и подобного рода ошибки крайне маловероятны, а представлены здесь для демонстрации очень крайнего случая.
Прежде чем переходить к визуализации LSM-дерева рассмотрим файловую структуру спейса на Vinyl.
Файловая структура спейса на Vinyl
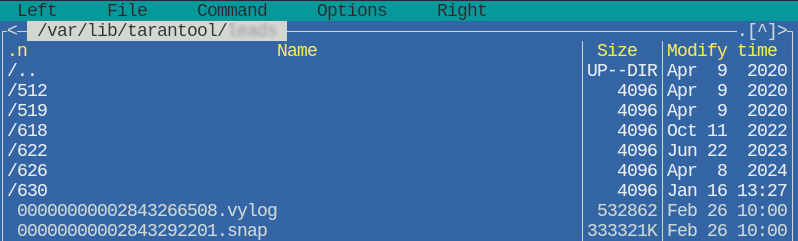
Vinyl сохраняет спейсы по пути vinyl_dir в директории с именем идентификатора спейса:
Идентификатор спейса можно узнать так:
127.0.0.1:3301> box.space.my_test_space.id
---
- 622
...
На скрине видно что есть еще файл .vylog в нем хранятся метаданные определяющие какие файлы данных к какому LSM-дереву относятся.
Кроме того есть файл .snap, в нем хранятся данные движка Memtx, а в эту директорию он попал потому что memtx_dir и vinyl_dir указывают на одну и ту же директорию.
Внутри директории спейса есть поддиректории именуемые цифрами, эти цифры означают нумерацию индексов:

На скрине видно, что у спейса 622 есть 3 индекса, причем мы можем их сопоставить с выводом:
127.0.0.1:3301> box.space.my_test_space.index
---
- 0: &0
unique: true
parts:
- type: string
is_nullable: false
fieldno: 1
id: 0
space_id: 622
name: primary
type: TREE
1: &1
unique: false
parts:
- type: integer
is_nullable: false
fieldno: 2
id: 1
space_id: 622
name: offer_id
type: TREE
2: &2
unique: false
parts:
- type: integer
is_nullable: false
fieldno: 3
id: 2
space_id: 622
name: created
type: TREE
offer_id: *1
primary: *0
created: *2
...
Итак: primary индекс под номером 0 соответствует директории с именем 0 и так далее.
А внутри директории мы видим 2 типа файлов:
.run: файл с данными - неизменяемый отсортированный наборов страниц.index: файл с данными индекса, эти файлы кэшируются в ОЗУ
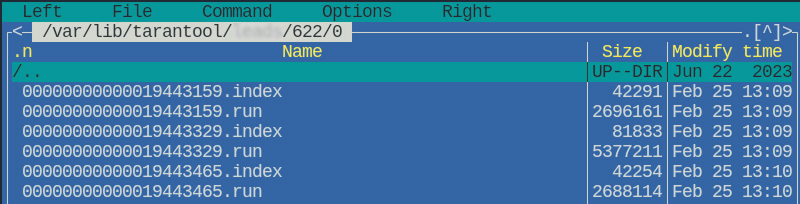
В директории vinyl_dir могут встречаться файлы .run.inprogress - это временные файлы создаваемые Tarantool во время дампа или компакции.
Визуализация хранилища Vinyl
В LSM-дереве все файлы организованы в пирамиду:
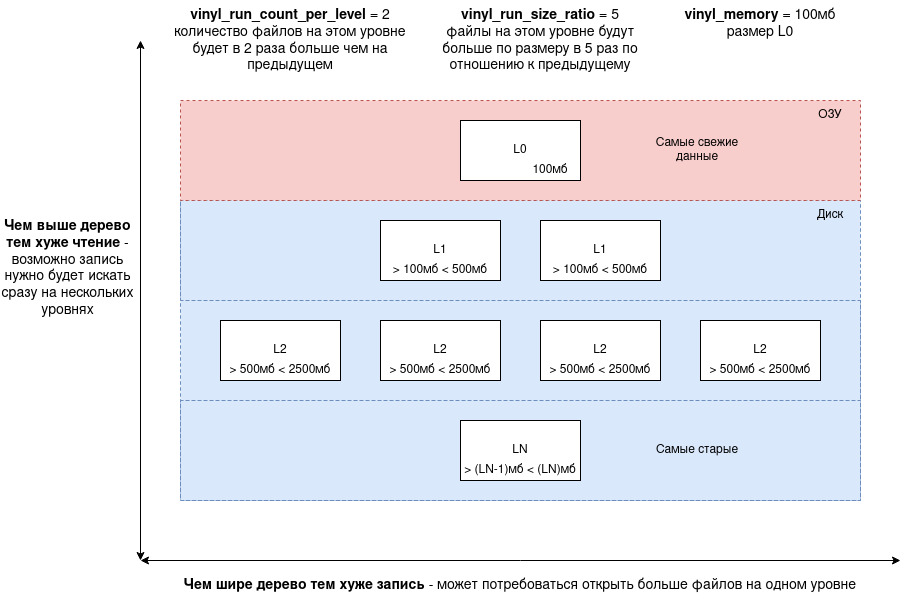
Пирамида обладает свойством ширины (количество файлов на уровень) и высоты (количество уровней).
Самый верхний уровень это L0, он находится в ОЗУ, все остальные уровни находятся на диске. Внезапно можно подумать что L0 это кэш, но нет.
Кэш в
Vinylэто готовые диапазоны значений индекса, по которому можно обратится к данным на диске.
Это отличается от классического представления, к которому мы привыкли, например в MySQL в движке InnoDB, где кэш представлен страницами памяти с данными таблицы загруженными из диска.
Чем новее операции с данными, тем выше они находятся в пирамиде, и как следствие на L0 находятся самые новые данные, которые еще не сброшены на диск.
Как данные перемещаются между уровнями?
После заполнения L0, данные сбрасываются в файл .run на диск на уровень L1.
Когда число файлов на уровне L1 превышает vinyl_run_count_per_level, то запускается компакция (рассмотрим ниже), она соединяет несколько .run-файлов в один и если размер итогового файла превышает размер файла на предыдущем уровне * vinyl_run_size_ratio, то файл спускается на уровень L2. И так далее.
Что в итоге хранится в .run-файле?
В .run-файле хранятся слепки кортежей. На самом высоком уровне хранится самая актуальная версия кортежа. Если этот же кортеж есть на нижних уровнях, то это старая его версия, чем ниже тем старее версия.
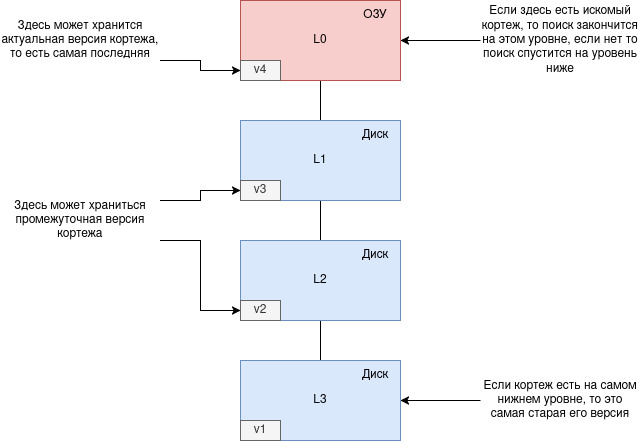
Как чистить старые версии кортежей рассмотрим позже.
Как высота и ширина пирамиды влияют на чтение и запись?
Если пирамида будет слишком высокой, то пострадают чтения, если слишком широкой – запись.
Высокая пирамида (много уровней, меньше данных на каждом уровне):
- Быстрая запись: уровни небольшие, и слияния затрагивают меньший объём данных, что делает их быстрее
- Медленное чтение: при чтении может потребоваться искать нужную запись сразу на нескольких уровнях
Широкая пирамида (мало уровней, больше данных на каждом уровне):
- Быстрое чтение: может потребоваться открыть больше файлов на одном уровне, но меньше шансов перейти на нижний уровень
- Медленная запись: слияния крупные, они требуют сливать большие объемы данных на уровень
Как управлять шириной и высотой LSM-дерева?
Есть 2 основных параметра:
vinyl_run_count_per_level: количество файлов на один уровень пирамиды умноженное на количество файлов на предыдщем уровне. НаL0всегда 1 файл в ОЗУ, еслиvinyl_run_count_per_level = 2, то файлы по уровням будут распределены примерно так:L0: 1->L1: 2->L3: 4->L4: 8->L5: 16vinyl_run_size_ratio: коэфициент размера файлов на текущем уровне относительно предыдущего. Если наL0размер 100мб (vinyl_memory = 100 * 1024 * 1024), аvinyl_run_size_ratio = 5, то размеры файлов по уровням будут примерно такие:L0: 100мб->L1: 500мб->L3: 2500мб->L4: 7500мб
Чем больше значение vinyl_run_count_per_level тем шире пирамида, а чем ниже значение тем она выше.
Чем больше vinyl_run_size_ratio тем более вместительными становятся уровни, а значит данные медленнее спускаются вниз по уровням при компакции. И наоборот: чем меньше vinyl_run_size_ratio тем больше вероятность роста пирамиды вниз, потому что данные на новом уровне не сильно больше вместительнее предыдущего, а значит нужно формировать новый уровень.
Фоновые процессы
Для движка Vinyl в Tarantool есть 2 фоновых процесса записи на диск, оба они приводят к образованию новых файлов .run, но задачи разные. Точнее именно эти 2 процесса обслуживают LSM-дерево: перестраивают пирамиду и перемещают данные между уровнями.
Когда объем данных в ОЗУ (LO-ая часть LSM-дерева) достигает лимита, например было много вставок, происходит сброс накопленных данных на диск: сначала создается файл .run.inprogress, в него записывается неизменяемый набор страниц данных и потом файл переименовывается в .run. Это процесс дампа.
Периодически, в зависимости от настроек, запускается компакция или слияние - объединение нескольких старых файлов .run на одном уровне пирамиды в новый файл. Слияние приведет к перезаписи всех данных на диске, поэтому если чтений мало, то лучше делать слияния реже.
Слияния в Tarantool всегда выполняются независимо от дампов, в отдельном потоке выполнения. Это возможно благодаря природе
LSM-дерева– после записи файлы в дереве никогда не меняются, а слияние лишь создает новый файл.
Кроме того есть процесс менеджера транзакций реализованного как MVTO (multiversion timestamp ordering, почитать можно здесь и здесь)
За чтение и декомпрессию отвечают отдельные потоки, их количество определяется параметром vinyl_read_threads.
Итого, в движке Vinyl есть как минимум 4 логических процесса:
- дамп
- компакция
- менеджер транзакций
- чтение и декомпрессия
Как работа Vinyl влияет на систему?
Используя iotop посмотрим как движок Vinyl в Tarantool влияет на систему.
При запуске Tarantool Vinyl интенсивно считывает данные из диска:

Штатная работа со спейсом на движке Vinyl выглядит редкими всплесками потребления диска и еще более редкими записями:

space:count() на движке Vinyl перебирает все кортежи спейса на диске и подсчитывает их количество, а значит будет большая и продолжительная нагрузка на диск в этот момент, которая зависит от размера спейса и ресурсов диска. В моей ситуации 15млн записей считались за ~2 минуты. Вывод iotop в данном случае такой:

Создание индекса также перебирает все кортежи на диске, но не просто для подсчета, а для создания индекса:

Здесь не только интенсивные чтения (vinyl.reader), но и запись (vinyl.compactio и vinyl.dump). Операция не быстрая, на 15млн записей уходит порядка 10 минут.
Компакция ведет к кратковременным интенсивным чтениям и записи:

Компакция сопровождается такими записями в логах:
Feb 26 17:10:57 server_name 02-26 17:10:57.165 [16211] vinyl.compaction.1/314/task I> writing `/var/lib/tarantool/profile/622/0/00000000000019479904.run'
Feb 26 17:10:57 server_name 02-26 17:10:57.166 [16211] vinyl.compaction.2/324/task I> writing `/var/lib/tarantool/profile/622/0/00000000000019479901.index'
Feb 26 17:10:57 server_name 02-26 17:10:57.167 [16211] main/107/vinyl.scheduler I> 622/0: completed compacting range (["f6a56b8a19b976d3cb305bc60382ddb4"]..["f7
655b421fe51c5be44c93c8397c5cb8"])
...
Feb 26 17:10:57 server_name 02-26 17:10:57.261 [16211] snapshot/101/main C> 1.8M rows written
Просмотреть Статистику компакции можно так:
localhost:3303> box.stat.vinyl().scheduler
---
dump_time: 592.51995058813
tasks_inprogress: 3
dump_output: 9379707189
compaction_queue: 86894599891
compaction_output: 23874432781
compaction_time: 1884.4598880341
dump_count: 55
tasks_failed: 0
tasks_completed: 402
dump_input: 3340484659
compaction_input: 68521174049
...
Здесь видно что tasks_inprogress имеет значение 3, а это значит что на данный момент в очереди 3 процесса выполнения компакции.
Очистка дерева от старых версий и удаленных кортежей
Теперь становится понятно что на нижних уровнях может скопиться большое количество неактуальных данных. Более того если произвести массовое удаление старых кортежей через space:delete(), то это ни на сколько не освободит место на диске, более того это займет еще больше пространства, потому что в LSM-дерево будут записаны операции удаления. Хотя казалось бы при компакции данные должны быть удалены с диска. А все дело в персистености данных Tarantool.
В Tarantool есть понятия контрольная точка или снэпшот. После создания снэпшота запускаются сборщик мусора Tarantool, это не тот же сборщик мусора в Lua.
Каждый снэпшот содержит список данных, на которые он ссылается. Снэпшот нужен для отката на версию данных, на которую он ссылается. Поэтому Tarantool не удаляет данные, на которые есть хотя бы одна ссылка из снэпшота.
Снэпшот создается командой box.snapshot(), а контрольные точки управляются следующими директивами:
- checkpoint_count: максимальное количество хранимых снэпшотов
- checkpoint_interval: как часто создается снэпшот
Представим ситуацию с такой конфигурацией:
box.cfg{
checkpoint_interval = 3600,
checkpoint_count = 48
}
Здесь снэпшоты создаются каждый час (3600 секунд), количество хранимых снэпшотов 48, а это значит что сервер Tarantool будет хранить историю всех кортежей за 48 часов. За это время может скопиться большое количество версий кортежей.
В моем случае при массовом удалении старых данных это стало критичным - диск почти заполнился неактуальными данными, от которых надо избавится.
Если есть полная уверенность в том, что старые версии кортежей больше не нужны, то можно сделать следующее:
- изменить конфиг
box.cfg{checkpoint_count = 1}, или оставить несколько последних снэпшотов - сделать снэпшот
box.snapshot()- Tarantool удалить старые снэпшоты и все версии данных, на которых больше нет ссылок
Теперь есть больше представления о том как под капотом в Tarantool работает Vinyl.
Для меня занимательным моментом оказалось то, что в Vinyl используется не классическое B-дерево, а именно LSM-дерево. Кроме того механизмы очистки старых версий данных более прозрачны чем в MySQL/MariaDB, но эти самые механизмы еще нужно понять)
По ходу эксплуатации Tarantool эта статья будет дополняться.