
ComfyUI Быстрый старт
- Примеры промптов и результатов
- Какое оборудование надо?
- А что по скорости?
- Установка ComfyUI
- Теория про генерацию в ComfyUI
- Первое использование
- Советы
- Что дальше?
После установки NVIDIA-драйвера и теста локальных LLM на llama.cpp я решил двинуться дальше и в начале 2026 года попробовал локальный ИИ с ComfyUI для генерации изображения и видео. Это оказалось достаточно просто и я был удивлен результатам. Вместо слов приведу 1 сгенерированную картинку девушки с тату адреса моего сайта, а так же 2 оживленные мои фотографии:



Примеры промптов и результатов
Приведу несколько примеров промптов и результатов, которые мне удалось получить на кастомном воркфлоу (схема почти в конце) с использованием диффузионной модели flux-2-klein-9b-fp8. Такие же результаты можете получить и вы, если дочитаете статью до конца.
Заброшенная железная дорога в лесу
Заброшенная железная дорога в лесу, густой туман, мох и цветы покрывают рельсы, мягкий рассветный свет, спокойная атмосфера. highly detailed, photorealistic, depth of field, cinematic composition, ultra realistic textures, nature reclaiming civilization.

Постапокалиптический город в стиле киберпанк
Позитивный промпт: Постапокалиптический город в стиле киберпанк, сломанные тусклые вывески, сломанные тусклые голограммы, природа захватывает улицы, темная атмосфера, кинематографическое освещение, драматические облака, ультрадетализация, фотореалистичность.
Негативный промпт: неон, яркие вывески, яркие голограммы, яркий свет

Ретро-космическая сцена
Позитивный промпт: Ретро-космическая сцена в стиле научной фантастики 1980-х годов, яркая туманность, светящиеся звезды, космический корабль с четкими линиями, драматическое освещение, цвета синтвейва, высокая детализация, кинематографическая композиция, постер.
Негативный промпт: modern style, photorealistic, blurry, low detail

Фантастический лес
Позитивный промпт: Фантастический лес со светящимися растениями, гигантскими древними деревьями, волшебной атмосферой, мягким туманом, кинематографическое фантастическое освещение, сверхдетализированными яркими цветами, фэнтезийная игра AAA, стиль Unreal Engine
Негативный промпт: realistic photography, low detail, blurry, flat lighting, lowres

Монолит - исполнитель желаний
Позитивный промпт: Мрачная сцена в стиле игры сталкер, внутри саркофага Чернобыльской АЭС, мрак, темно, огромный светящийся Монолит (исполнитель желаний) в центре зала, очень большой просторный зал, вокруг лежат тела сталкеров в потрёпанных защитных костюмах, догорает костёр, тусклый оранжевый свет огня смешивается с холодным слабым голубым свечением Монолита, пыль в воздухе, ржавый металл, бетон, индустриальные руины, постапокалипсис, гнетущая атмосфера, кинематографичный свет, объемный свет, высокая детализация, фотореализм, широкоугольный кадр, масштабная сцена. густой туман, аномальное свечение, искры в воздухе, зловещие тени, тревожная атмосфера, слабое мерцание света, глубокие тени, дым.
Негативный промпт: мультяшный стиль, аниме, яркие цвета, размытость, низкое качество, плохая анатомия, лишние конечности, чрезмерная кровавость, текст, водяной знак, пересвет, плоское освещение, стены, потолок

Женщины
И конечно, без женщин никуда, особенно в теме фантазий вольной реализациии. Здесь даже есть отдельные направления по созданию моделей для инфлюенсеров с последующей монетизацией. Но мы не будем вдаваться так глубоко, а лишь немного заглянем за ширму возможностей.
Позитивный промпт: Две взрослые женщины с пышной грудью в стильном современном лофте, смотрят друг на друга и общаются, большие окна, мягкий дневной свет, женщины в сорочках, спокойные уверенные позы на диване, естественная кожа, лёгкая чувственность, модная фотосессия, высокая детализация, фотореализм, мягкая глубина резкости. Одна женщина что-то экспрессивно рассказывает, а другая естественно смеется. Одна блондинка, другая брюнетка.
Негативный промпт: Пошлый стиль, чрезмерная откровенность, плохая анатомия, лишние конечности, низкое качество, шум, пересвет, одинаковые лица

Какое оборудование надо?
Я запускаю генерацию в ComfyUI на:
MB: MSI B450-A PROCPU: AMD Ryzen 7 5800xRAM:4x16gb3200mhzGPU: Gigabyte RTX 3090 GAMING OC илиTesla V100 16gb
Можно и без видеокарты, но нужно чтобы хватало
RAM. В моих экспериментах потреблениеRAMдоходило до50гб.
А что по скорости?
На видеокарте генерация происходит конечно же быстрее, однако, даже 24gb на RTX 3090 не хватает для некоторых задач.
Все картинки выше я генерировал с использованием Tesla V100 16gb и части RAM, скорость 15-30 секунд.
2 видео выше, генерировались на RTX 3090 24gb ~7 минут.
Установка ComfyUI
Судя по документации на момент установки ComfyUI, самая подходящая версия python 3.12, а так как на Debian 12 по дефолту стоит 3.11 значит придется с этим что-то делать. Обновлять целиком я не осмелился, а вот попробовать pyenv для установки разных версий python решил попробовать.
Для начала необходимо установить NVIDIA-драйверы.
pyenv
В минимальном варианте установка происходит от обычного пользователя (суперпривелегии не нужны), под которым будем запускать ComfyUI:
$ curl -fsSL https://pyenv.run | bash
Для тех кто хочет держать под контролем то что он устанавливает, то можно так:
$ curl -fsSL https://raw.githubusercontent.com/pyenv/pyenv-installer/master/bin/pyenv-installer > pyenv-installer.sh
# изучаем что там делается в скрипте и запускаем
$ bash pyenv.sh
Просмотреть список доступных версий для установки можно так:
$ pyenv install --list
А вот так устанавливаем конкретную версию:
$ pyenv install -v 3.12
Теперь нам нужно зайти в директорию где будет у нас ComfyUI и установить на эту директорию кастомную версию python, чтобы при вызове python всегда использовалась нужная нам версия:
$ pyenv local 3.12
Однако, это надо сделать после клонирования репозитория ComfyUI в самой директории проекта.
Установка и первый запуск ComfyUI
Клонируем репозиторий и переходим в директорию репозитория:
$ git clone https://github.com/Comfy-Org/ComfyUI.git
$ cd ComfyUI
Переключаемся с main-ветки на конкретный релиз, потому что основная ветка может быть нестабильной:
$ git checkout v0.11.1
В момент установки была актуальна версия v0.11.1, сейчас уже вышли новые версии.
Создаем виртуальнео окружение и переключаемся на него:
$ python -m venv .venv
$ source .venv/bin/activate
Теперь нам нужно установить PyTorch библиотеку. Инструкция говорит нам устанавливать для работы с CUDA 13, но у меня есть старые карты, например Tesla P40 (CC 6.1) и Tesla V100 (CC 7.5), где на первой поддерживается только CUDA 12. Поэтому я ставлю для версии 12:
$ pip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu120
ComfyUI не поддерживает compute capability ниже
7.0, а значит не заведется на Tesla P40. Но на Tesla V100 работает, поэтому возня выше не имеет смысла, ставьте сразу PyTorch для CUDA 13.
Устанавливаем зависимости:
$ pip install -r requirements.txt
Генерируем самоподписанный сертификат на 10 лет:
$ openssl req -x509 -newkey rsa:4096 -keyout key.pem -out cert.pem -sha256 -days 3650 -nodes -subj "/C=XX/ST=StateName/L=CityName/O=CompanyName/OU=CompanySectionName/CN=CommonNameOrHostname"
И запускаем:
$ python main.py --tls-keyfile key.pem --tls-certfile cert.pem --port 8443 --listen 0.0.0.0
Переходим на https://localhost:8443 и мы должны увидеть что-то подобное:
Установка ComfyUI-Manager
Останавливаем ComfyUI путем нажатия Ctrl+C.
ComfyUI-Manager - это расширение, предназначенное для повышения удобства использования ComfyUI. Сейчас мало что понятно, но лучше сразу его установить.
Оказывается, в репозитории ComfyUI уже есть инструкция по установке, но я ее как-то проглядел и установил вручную по инструкции из репоизтория ComfyUI-Manager.
В директории ComfyUI перейти в custom_nodes:
$ cd custom_nodes
Склонировать репозиторий и перейти в его директорию:
$ git clone https://github.com/ltdrdata/ComfyUI-Manager comfyui-manager
$ cd comfyui-manager
Переключаемся на конкретный релиз (на момент установки это 4.1b1):
$ git checkout 4.1b1
Еще раз запускаем ComfyUI и теперь там должно быть такое:
Теория про генерацию в ComfyUI
Кратко рассмотрим необходимый минимум теории, чтобы иметь представление о происходящем.
Checkpoint (Diffusion Model) - основная модель для генерации, часто файл с расширением .safetensors. На reddit есть обсуждение, что такое checkpoint и чем это отличается от LoRA. А в этом обсуждении есть интересный документ с разными ссылками на модели. Вот несколько моделей wan2.2, Qwen-Image, Z-Image, LTX-2.3.
Латентное пространство - векторное представление уменьшенной в несколько раз картинки или видео. Как правило, это многомерный числовой массив (тензор). Для ИИ это не просто пространство пикселей, а пространство смыслов, форм и структур. На изображении ниже латентное пространство подписано как Bottleneck:
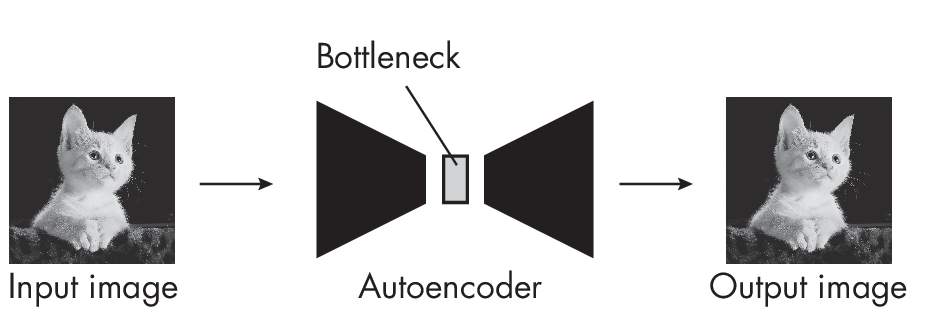
VAE (Variational AutoEncoder) - модель, которая работает с латентным пространством, на скрине выше это AutoEncoder, бывает:
- Encode - преобразование изображения в латентное пространство
- Decode - преобразование латентного пространства в изображение
CLIP - модель, которая обрабатывает текстовый промпт. И здесь есть:
- Positive Prompt - что нужно рисовать
- Negative Prompt - что нужно исключить
LoRA (Low-Rank Adaptation) - дополнительная мини-модель для изменения стиля, например, чтобы генерировать изображения или видео в стиле аниме.
Пример промпта:
Взрослая девушка с подтянутой фигурой и пышной грудью в движении, шаг вперёд, развевающиеся волосы и одежда, энергичная поза, выразительная мимика, сложная композиция кадра, эффект глубины, детализированные текстуры, световые акценты, контраст света и тени, высокая детализация кожи и одежды. San Andreas graphic. low poly. vertex shading.
На примере этого промпта и результата можно увидеть разницу, которую способна дать LoRA-модель. Справа результат без LoRA, он вовсе не похож на стиль игры GTA San Andreas, а слева на том же самом сиде (204468990964528) результат с LoRA GTA San Andreas Style:

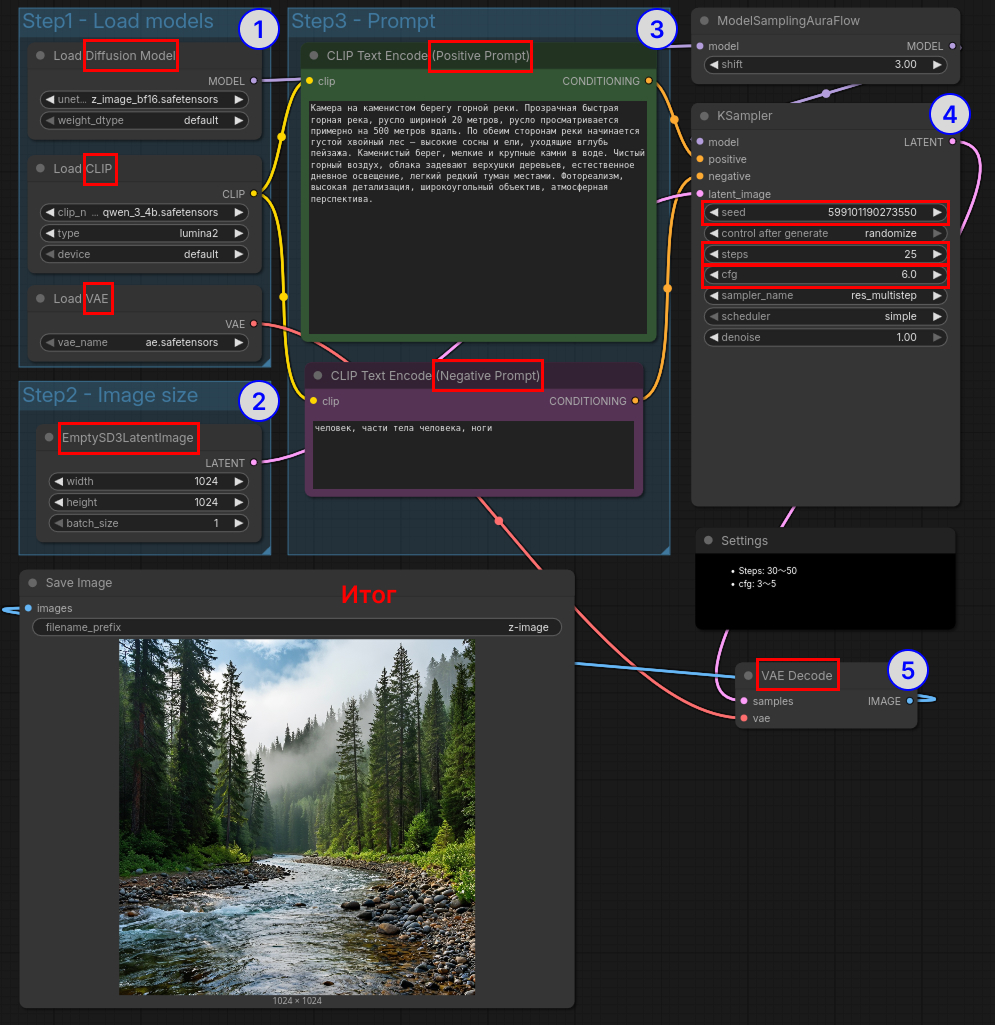
Empty Latent Image - пустое латентное пространство, как правило, это нода задающая параметры изображения. Это будем использовать в случае генерации изображения из промпта.
Batch Size — количество изображений за один прогон. Содержится в ноде Empty Latent Image. Как правило, здесь значение 1, но можно поставить 2, и тогда за одну генерацию можно получить сразу 2 разных изображения, при этом не обязательно падение скорости в 2 раза.
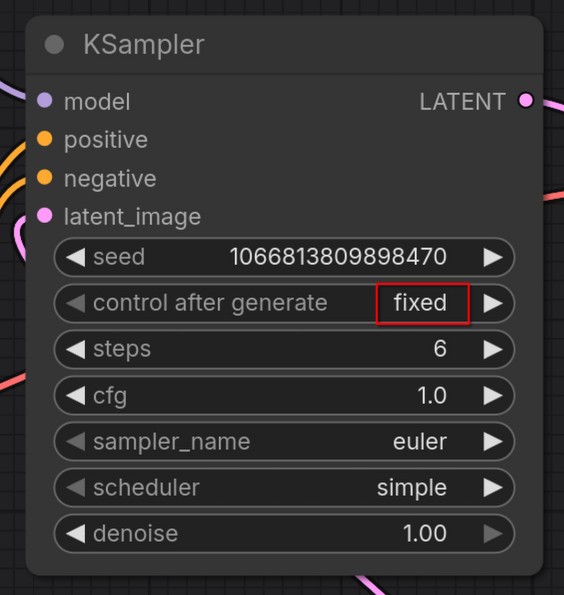
KSampler — ключевая нода, которая выполняет сам процесс диффузии, в ней есть:
- Seed - число, определяющее случайность генерации, если это значение будет одинаковое на каждой генерации, то будут одинаковые результаты.
- Steps - количество шагов генерации
- CFG (Classifier Free Guidance scale) - на сколько сильно результат должен соответствовать промпту. Низкий
CFG→ больше творчества у модели, ВысокийCFG→ жёсткое следование тексту
А на этом скрине выделена каждая сущность описанная выше:
Первое использование
Мы не будем погружаться в глубину и исследовать детали, наша цель быстрое знакомство, чтобы понять что это такое. Поэтому пойдем заранее проторенной дорожкой подготовленных воркфлоу.
В левом меню выберем Templates и настроим фильтр по типу шаблона и возможности его развертывания через ComfyUI, ведь нас интересую локальные модели ИИ, которые мы будем разворачивать на своем компьютере:
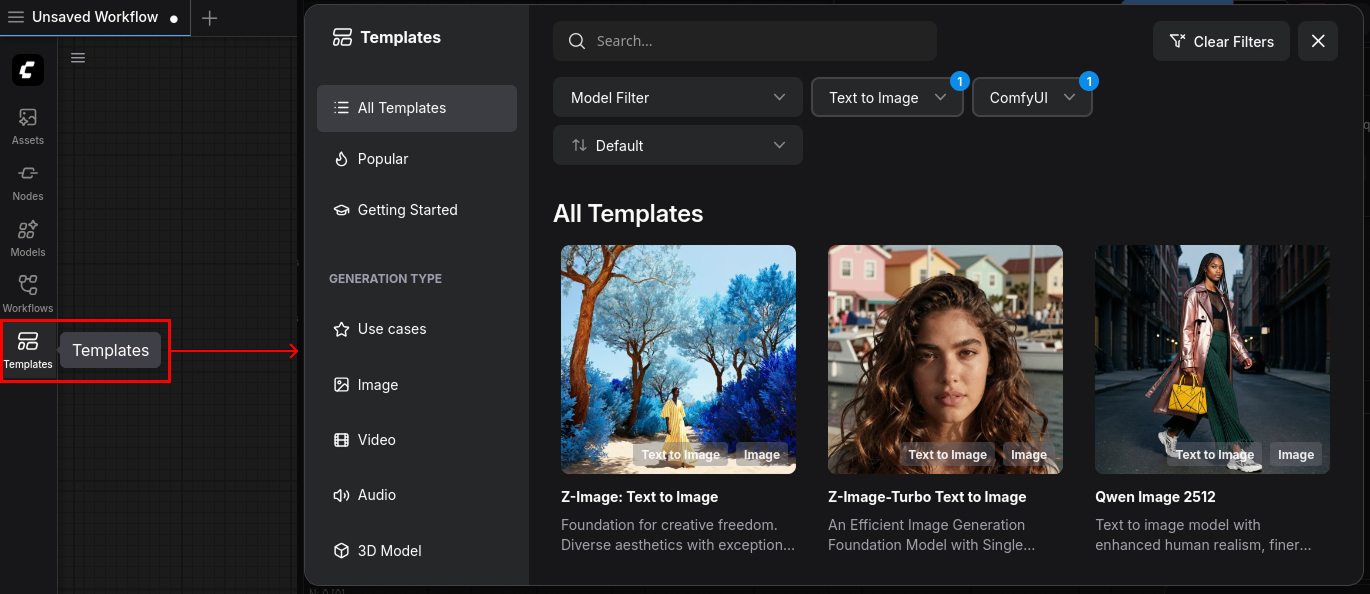
На скрине выше я выбрал тип шаблона Text to image и способ запуска ComfyUI. Теперь выбираем любой понравившийся воркфлоу. Для начала советую взять:
Flux.2 [Klein] 9B: Text to image: для генерации картинок из текстаWan 2.2 14B: Text to video: для генерации видео из текстаWan 2.2 14B: Image to video: для генерации видео из текста и картинок
После выбора скорее всего вы увидите такое окно, в котором говориться что у вас на ПК отсутствуют необходимые модели для выбранного воркфлоу:
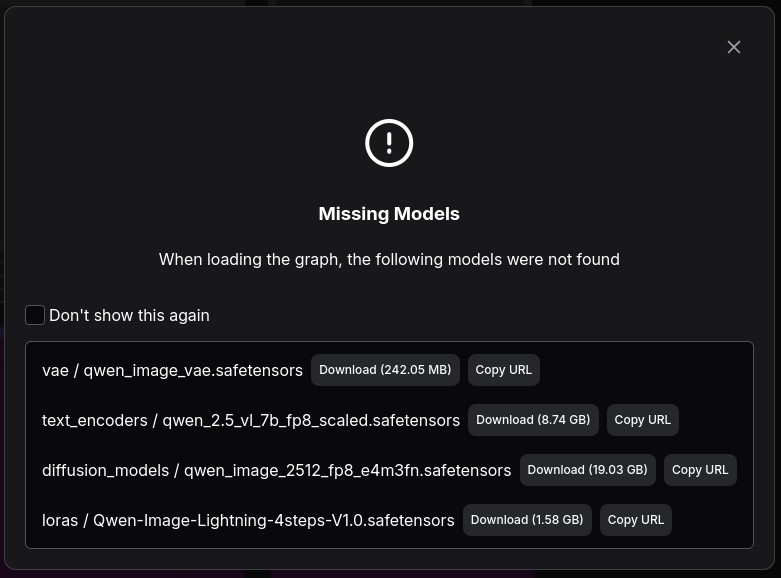
Не закрываем окно, переходим в терминал где развернут ComfyUI, а именно в директорию models и идем по порядку:
- нажимаем
Copy URL - переходим в нужную директорию, она указана перед названием модели (
vae,text_encoders,diffusion_models,lorasи т.д.) - в терминале вводим
wget, вставляем из буфера обмена ссылку и скачиваем модель
Если модель не скачивается по причине
401, то нужно зайти на страницу модели и принять соглашение (при этом нужно авторизироваться на HuggingFace), после чего можно скачать модель используя токен HuggingFace.
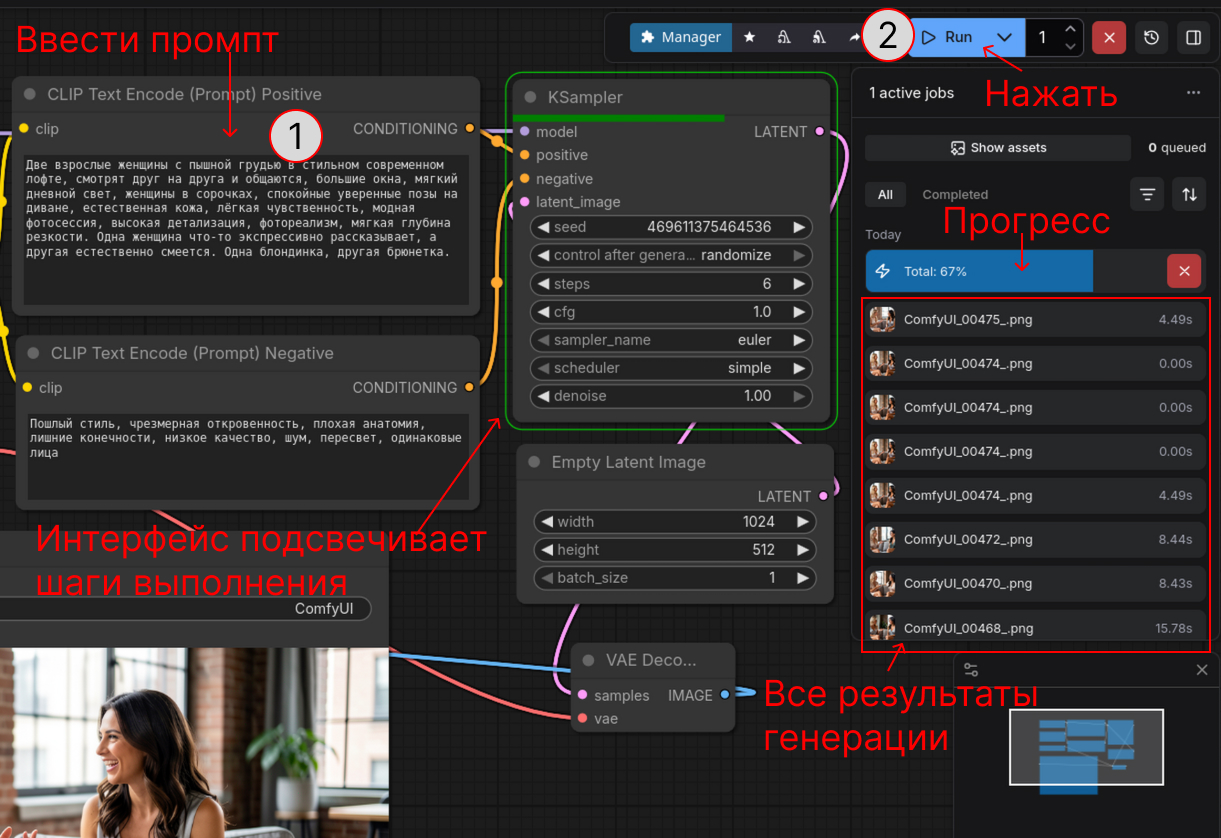
После завершения скачивания всех моделей обновите страницу, введите промпт и нажмите Run:
Советы
Для начала используйте готовые воркфлоу из раздела Templates, они простые и помогут быстро влиться.
Используйте меньшее разрешение при генерации, например вместо 1024х1024 используйте 256х256, это значительно ускорит получение результата, и вы сможете быстрее понять как модель реагирует на изменения в ваших промптах.
Когда на малом разрешении поймете что добились чего хотели:
- зафиксируйте сид
- увеличьте разрешение
- запустите долгую генерацию
Так вы быстрее придете к желаемому результату.
Что дальше?
Если хотите пойти дальше в изучение ComfyUI, то советую видео по основам ComfyUI и видео по основам воркфлоу.