Fibers - кастомные скрипты в Tarantool
- Что такое fiber?
- Как устроены fiber в Tarantool?
- Примеры fiber в Tarantool
- Администрирование файберов
- Логирование и мониторинг
Представим ситуацию, когда нам нужно периодически обновлять данные, скорее всего на основании времени, или вообще просто обновлять. Это могут быть различные операции и одна из таких это протухание данных (истечение срока жизни - TTL).
Tarantool как и Redis является key-value базой данных, однако в Tarantool Community Edition нет встроенного механизма протухания данных как в Redis. Для бесплатной версии можно использовать модуль expirationd, а в Enterprise версии есть RESP, где поддерживается REDIS API, а там внутри уже есть EXPIRE. А в Community версии мы будем довольствоваться и без того широким функционалом - кастомными скриптами.
Кастомные скрипты могут использоваться для реализации различной логики, а TTL это лишь одно из проявлений. Например, можно использовать кастомную репликацию в скриптах или отправлять данные в другое хранилище, все ограничено применимостью для конкретного случая.
Кастомные скрипты в Tarantool пишутся на языке Lua, а механизм реализации называется fiber. Документация про fiber простая и понятная, а мы копнем немного глубже и разберем практическое использование.
Что такое fiber?
Fibers – легковесные задачи (потоки), управляемые самим приложением, а не операционной системой.
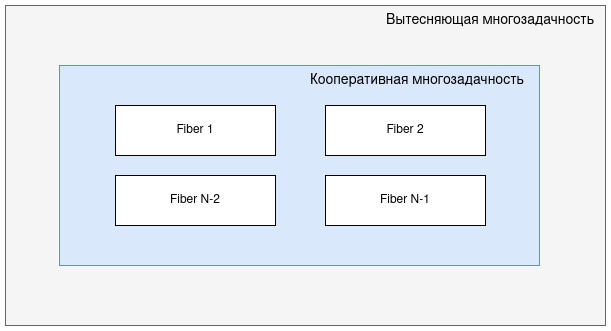
Чтобы лучше понять о чем речь, нужно вспомнить про понятие многоазадчности с ее видами:
- Вытесняющая многозадачность: задачи никогда не думают о других задачах, они конкурируют за ресурсы, поэтому ОС сама принимает решение о переключении выполнения задач
- Кооперативная многозадачность: задачи сотрудничают и добровольно уступают управление, при бездействии или при блокировке, ОС никогда не вмешивается в управление
Нетрудно догадаться что fiber относится к кооперативной многозадачности.
Концептуально файбер выступает конечным высокоуровневым элементом многозадачности в среде Tarantool, где на верхнем уровне идет вытесняющая многозадчность со всеми элементами, ниже кооперативная, а внутри нее мы создаем файберы.
Как устроены fiber в Tarantool?
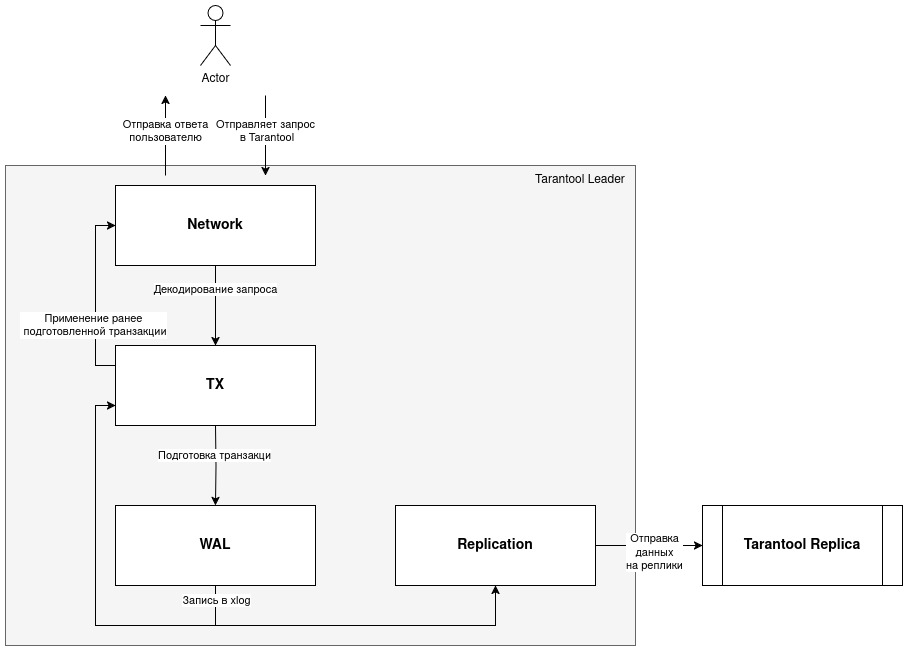
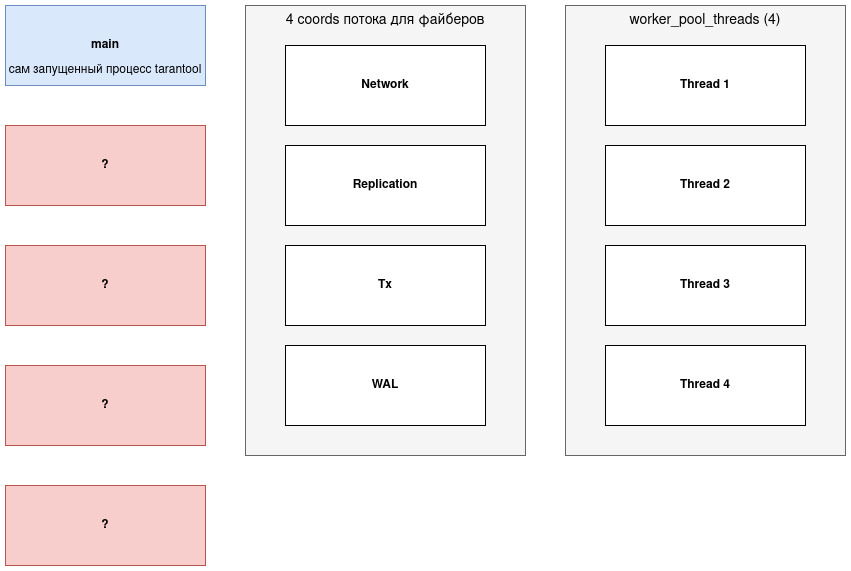
Судя по документации для разработчиков, в Tarantool есть 4 выделенных потока (именуемых coords) для логического разделения файберов:
- Network: принимает запросы на управление и изменение данных.
- Replication (Applier, Relay): лидер отправляет данные репликам, а реплики получают данные от лидера.
- Tx: через этот поток проходят все изменения в базе данных
- WAL: поток работы с журналом упреждающей записи.
Потоки могут взаимодействовать между собой:
Если попробовать получить список файберов, то увидим примерно такой вывод (здесь было несколько main и applier, я оставил только уникальные файберы):
localhost:3303> fiber.info({bt = false})
- 4876301:
csw: 612813920
memory:
total: 586104
used: 67741
time: 0
name: main
fid: 4876301
105:
csw: 25273216
memory:
total: 516472
used: 0
time: 0
name: gc
fid: 105
106:
csw: 4487
memory:
total: 516472
used: 0
time: 0
name: checkpoint_daemon
fid: 106
115:
csw: 2017040
memory:
total: 192807288
used: 185526952
time: 0
name: applier/replicator@172.18.0.53:3303
fid: 115
107:
csw: 36868561
memory:
total: 516472
used: 0
time: 0
name: memtx.gc
fid: 107
125:
csw: 1000
memory:
total: 516472
used: 0
time: 0
name: guard of feedback_daemon
fid: 125
101:
csw: 1
memory:
total: 516472
used: 0
time: 0
name: lua
fid: 101
109:
csw: 575785
memory:
total: 516472
used: 0
time: 0
name: vinyl.vylog_flusher
fid: 109
126:
csw: 8168
memory:
total: 516472
used: 0
time: 0
name: feedback_daemon
fid: 126
118:
csw: 27
memory:
total: 516472
used: 0
time: 0
name: raft_worker
fid: 118
108:
csw: 1170427
memory:
total: 516472
used: 0
time: 0
name: vinyl.scheduler
fid: 108
130:
csw: 1933277
memory:
total: 520568
used: 0
time: 0
name: applierw/replicator@172.18.0.53:3303
fid: 130
104:
csw: 1
memory:
total: 516472
used: 0
time: 0
name: console/unix/:/var/run/tarantool/main.control
fid: 104
...
Примерное описание файберов из вывода:
main: основной цикл обработки событийgc: сборщик мусора объектов Luacheckpoint_daemon: периодический файбер для создания контрольных точекapplier/replicator: получение данных репликацииapplierw/replicator: запись данных при репликацииmemtx.gc: сборщик мусора для освобожденных кортежей в движке Memtxguard of feedback_daemonиfeedback_daemon: файберы сбора статистики и защиты от сбоевlua: интерпретатор lua для пользовательского кодаvinyl.vylog_flusher: запись служебной информации журнала Vinylvinyl.scheduler: файбер компакции для движка Vinylraft_worker: файбер для RAFT, чтобы кластер мог переизбирать лидераconsole/unix/:/var/run/tarantool/main.control: файбер обработки сессии в терминале, где была выполнена команда
Некоторые файберы можно сгруппировать и отнести к определенному потоку, о которых говорили ранее. Например, очевидно что applier/replicator, applierw/replicator и raft_worker относятся к Replication. А console/unix может быть завязана на Network или Tx. checkpoint_daemon, memtx.gc, vinyl.scheduler, feedback_daemon по контексту больше относятся к Tx.
В htop видно несколько строк Tarantool - это потоки, среди которых есть потоки для файберов:
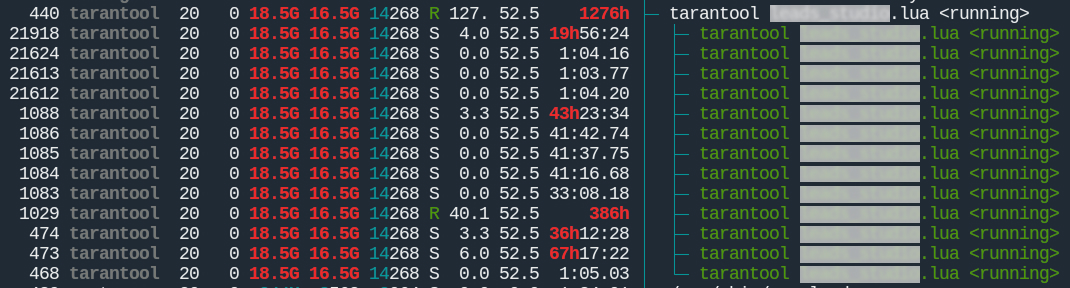
Если 1 основной поток, 4 потока для файберов, а на скрине 13 потоков, что делают остальные 8?
Частично, ответ можно найти в директиве worker_pool_threads, она устанавливает максимальное количество потоков для внутренних процессов. В данном случае значение директивы 4. И еще у нас остается 4 потока (13-5-4=4), возможно это технические потоки самого приложения, движков хранения и низкоуровневых библиотек, которые сами себе создают потоки.
Примеры fiber в Tarantool
Файберы создаются кодом в bootstrap файле либо в сеансе утилиты tt (бывший tarantoolctl).
Простой пример создания файбера:
-- обязательно подключаем пакет с API для fiber
fiber = require('fiber')
-- код файбера - простая функция
function my_fiber()
print('Hello world!')
end
-- запуск файбера
fiber_instance = fiber.create(my_fiber)
Файберы выполняют свою логику и должны при этом заботиться о других файберах в очереди на выполнение. Это достигается путем уступок двух видов:
- Явная: в коде файбера вызывается fiber.yield() или fiber.sleep(t), тем самым файбер временно отдает управление планировщику файберов
- Неявная: когда файбер делает операции ввода/вывода и они блокируют его дальнейшее выполнение, тогда планировщик понимает что файбер будет простаивать до тех пор, пока ресурс не будет готов и переключает выполнение на другой файбер
Некоторые примеры для неявной уступки:
- открытие сетевого соединения, например во время
HTTP-запроса - запись/чтение файлов на/с диска
- запись данных в спейс на движке Vinyl
Рассмотрим пример, когда логика работы файбера может быть зациклена бесконечно, но при этом в коде файбера есть уступки выполнения:
fiber = require('fiber')
-- код файбера
function my_fiber()
while true do
-- проход по всем кортежам спейса на движке vinyl - неявная уступка
-- в момент чтения данных с диска
for key, value in box.space.my_vinyl_space:pairs() do
-- какая-то логика
end
-- передача управления другим файберам - явная уступка
fiber.yield()
-- или сон на 30 секунд (явная уступка) пока другие файберы выполняются
-- fiber.sleep(30)
end
end
-- запуск файбера
fiber_instance = fiber.create(my_fiber)
Кроме того файберам можно назначить имя чтобы их проще было найти в списке (рассмотрим чуть позже):
local job_name = 'my_fiber'
function my_fiber()
-- логика
end
fiber_instance = fiber.create(my_fiber)
fiber_instance:name(job_name)
Мы рассмотрели лишь самую малую часть работы с файберами, этого вполне достаточно чтобы уже начать писать свои файберы, однако возможности обширные, дальше с ними можно ознакомиться в документации.
Администрирование файберов
Как правило, администрирование файберов сводится к трем операциям:
- получить список файберов: fiber.info():
localhost:3303> fiber.info({bt = false})
- 123: -- идентификатор
csw: 612813920
memory:
total: 586104
used: 67741
time: 0
name: main -- название
fid: 123 -- идентификатор
- получить информацию по конкретному файберу: fiber.find(123)
- уничтожение файбера по
fid: fiber.kill(123)
Логирование и мониторинг
Несмотря на возможности администрирования файберов, их полезная нагрузка, остается неизвестной. И это может привести к нежелательным последствиям, что и произошло в моем случае.
Файбер реализовывал логику
EXPIREкак в Redis, но в какой-то момент данных стало слишком много, а файбер обрабатывал все меньше и меньше данных за итерацию, и все это вылилось в инцидент с распухшим спейсом, сломанным индексом и забитым диском на критически важном сервере.
Поэтому стоит сразу озадачиться логированием и мониторингом работы файбера, дабы понимать, как и что он делает. Давайте разбираться как это делать.
Логирование
Для логирования можно использовать модуль log:
fiber = require('fiber')
-- подключаем модуль log
log = require('log')
-- код файбера
function my_fiber()
-- лимит удаления за одну итерацию
local limit_delete = 1000
-- сколько всего было удалено за все время жизни этого файбера
local amount_deleted = 0
while true do
-- время когда запись считается протухшей
local expire_time = math.floor(fiber.time()) - 2592000
-- сколько удалено за эту итерацию
local iteration_deleted = 0
-- вывод в лог предварительных данных
log.info(string.format(
'fiber [%s]: start iteration, expire %d, limit %d',
job_name,
expire_time,
limit_delete
))
for key, value in box.space.my_vinyl_space:pairs() do
-- какая-то логика удаления
iteration_deleted = iteration_deleted + 1
if iteration_deleted >= limit_delete then
break
end
end
-- вывод в лог итогов работы одной итерации файбера
log.info(string.format(
'fiber [%s]: iteration deleted %d, amount deleted %d',
job_name,
iteration_deleted,
amount_deleted
))
fiber.yield()
end
end
fiber_instance = fiber.create(my_fiber)
Примерно так может выглядеть лог файбера:

При этом стоит проверить значение в log_level в конфиге Tarantool, чтобы эта директива не фильтровала тип сообщения, который записывает файбер. Например, если вы используете log.info, то в директиве log_level нужно установить значение не меньше 5 (info), чтобы info не подавлялись.
Теперь можно смотреть логи в том месте куда вы настроили вывод в конфиге, например в syslog.
Мониторинг
Для мониторинга в документации Tarantool есть отдельный раздел, и он слегка про другое, нас интересуют метрики бизнес-логики. Давайте разберем что именно нам нужно.
Предположим, что у нас есть файбер, который реализует удаление кортежей из спейса по определенному признаку, для примера это может быть протухание данных, как уже упоминалось неоднократно.
В этом случае нас интересует: сколько фактически файбер удаляет за одну итерацию, сколько она длится, когда была последняя итерация. Каждая из этих метрик может нам охарактеризовать работу файбера:
- Количество удалений за одну итерацию: если файберу установлен лимит удалений за одну итерацию в 1000 кортежей и файбер всегда удаляет только по 1000, то скорее всего он не справляется с объемом работы, а значит долг на удаление копится и может стать проблемой
- Длительность одной итерации: если произошел рост времени, то это странно, и надо бы выяснить
- Когда была последняя итерация: если файбер выполняется каждые 30 секунд, а последняя итерация была 10 минут назад, то значит с файбером что-то не так
Идея реализации подобного мониторинга заключается в следующем:
- создаем специальный спейс на движке
memtxдля хранения метрик (описание ниже):
box.schema.create_space('fiber_metrics', {
format = {
{name = 'fiber_name', type = 'string'},
{name = 'total_processed', type = 'number'},
{name = 'last_iteration_count', type = 'number'},
{name = 'total_iterations', type = 'number'},
{name = 'total_time', type = 'number'},
{name = 'avg_time', type = 'number'},
{name = 'last_update', type = 'number'}
}
})
box.space.app_fiber_metrics:create_index('primary', {
parts = {'fiber_name'}
})
- в коде файбера на каждой итерации обновлем метрики:
fiber = require('fiber')
-- код файбера
function my_fiber()
local metrics = box.space.fiber_metrics
-- лимит удаления за одну итерацию
local limit_delete = 1000
-- сколько всего было удалено за все время жизни этого файбера
local amount_deleted = 0
while true do
local start_time = fiber.time64()
-- время когда запись считается протухшей
local expire_time = math.floor(fiber.time()) - 2592000
-- сколько удалено за эту итерацию
local iteration_deleted = 0
for key, value in box.space.my_vinyl_space:pairs() do
-- какая-то логика удаления
iteration_deleted = iteration_deleted + 1
if iteration_deleted >= limit_delete then
break
end
end
metrics:update(fiber_name, {
{'+', 'total_processed', iteration_deleted},
{'=', 'last_iteration_count', iteration_deleted},
{'+', 'total_iterations', 1},
{'+', 'total_time', fiber.time64() - start_time},
{'=', 'avg_time', metrics:get(fiber_name).total_time / metrics:get(fiber_name).total_iterations},
{'=', 'last_update', fiber.time64()}
})
fiber.yield()
end
end
fiber_instance = fiber.create(my_fiber)
- на стороне системы мониторинга собираем метрики
Исходя из кода мы имеем следующие метрики:
total_processed(тип Counter): сколько всего было удалено кортежейlast_iteration_count(тип Gauge): сколько удалено кортежей за последнюю итерациюtotal_iterations(тип Counter): сколько всего было сделано итерацийtotal_time(тип Counter): сколько всего времени было потрачено на все итерацииavg_time(тип Gauge): среднее длительность итерацииlast_update(тип Gauge): время завершения последней итерации
Как это использовать? Например, на долго не изменяющийся last_update можно повесить триггер, рост avg_time на графике будет показательным, а график количества удаленных записей в минуту может выглядеть так:
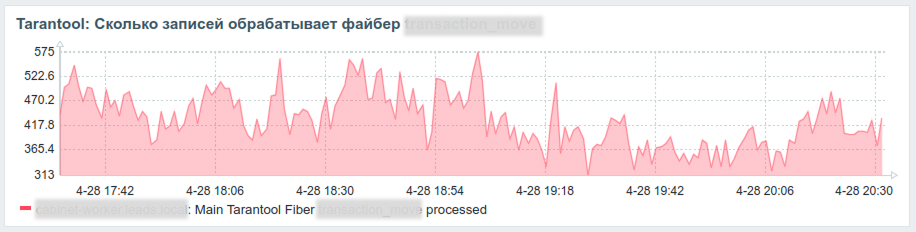
На все критические файберы мы повесили такой мониторинг и построили графики, теперь мы точно знаем что происходит с каждым файбером и есть ли в них проблема.
Для меня файберы в Tarantool стали открытием кооперативной многозадчности, точнее я слышал о ней раньше, но понял как это работает только здесь. К тому же, это еще одна попытка покодить на моем первом языке программирования Lua :)
Для дальнейшего изучения файберов в Tarantool конечно же нужно идти в документацию по приведенным ссылкам в статье.