
Расшифровка звука через Whisper локально
- Терминология
- Аппаратная часть
- Тестовый пример
- Whisper от OpenAI
- whisper.cpp
- Faster Whisper
- WhisperX
- whisper-asr-webservice
- speaches.ai
- Whisper-WebUI
- Другие проекты
- Итоги
После того как я развернул на своем сервере локальную LLM и внедрил ее в OpenWebUI я наткнулся на непонятные для меня вещи, а именно как работает аудио в ИИ и какие есть модели? А началось все с этого раздела, а заполнил я его уже под конец написания этой статьи:
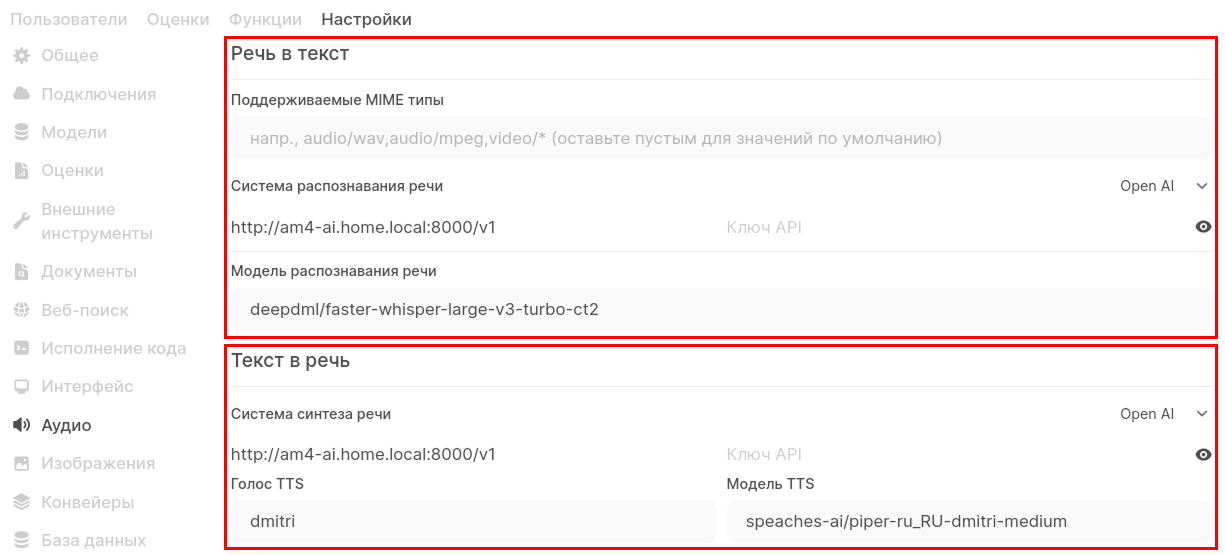
Поэтому сейчас мы это разберем на конкретном примере модели ИИ для работы с аудио Whisper от OpenAI.
Модель Whisper вышла в 2022 году и за несколько лет активной эксплуатации комьюнити значительно выросло и создало множество реализаций и улучшений, которые мы с вами рассмотрим в этой статье. А некоторые из представленных решений продолжают развиваться и по сей день (на момент написания статьи март 2026 года).
Терминология
Вокруг ИИ в сфере аудио есть несколько терминов, которые нам необходимо рассмотреть прежде чем мы продолжим дальше.
ASR (Automatic Speech Recognition, автоматическое распознавание речи) - преобразует звуковую волну, в которой говорит человек, в текстовую строку: 🎤 ➜ 🧠🤖 ➜ 📝
STT (Speech‑to‑Text, речь‑в‑текст) - то же что и ASR. Иногда под STT подразумевают готовый сервис с дополнительными функциями (автоматическое определение языка, пунктуации, адаптация к голосу): 🗣️ ➜ 🎤 ➜ 📝
И тут возникает недопонимание, а в чем же разница между ASR и STT?
Когда мы говорим про
ASRто обсуждаем модели ИИ, например Whisper, качество распознавания, языки и прочие характеристики самой технологии. А когда говорим проSTTто это больше проAPI, кнопку "Диктовать" в приложении. Иными словами:STTэто частный случайASR.
TTS (Text‑to‑Speech, Текст‑в‑речь) - преобразует текстовую строку в естественно звучащую речь: 📄 ➜ 🧠🤖 ➜ 🔊
Транскрибация (transcription) - процесс перевода аудиозаписи (разговор, лекция, интервью) в текст: 📝 ➜ ✍️ ➜ 📄
Диаризация (Speaker Diarization) - разделяет многоголосый аудиофайл на сегменты, привязывая каждый сегмент к конкретному говорящему: 🗣️👩 ➜ 🎤 ➜ 👥📝
Если изобразить схематично путь голоса от человека до текста и обратно в голос, то будет выглядеть примерно так:

Теперь когда мы разобрались в терминах уточним о чем мы будем говорить дальше.
В первую очередь меня интересовала транскрибация (STT) для OpenWebUI.
Как оказалось позже, через один из рассматриваемых проектов, можно прикрутить TTS для озвучивания ответов ИИ все там же в OpenWebUI.
И как побочный результат мне стала интересна диаризация, ее мы тоже рассмотрим.
Аппаратная часть
Все эксперименты я проводил на тестовом стенде:
MB: MSI B450-A PROCPU: AMD Ryzen 7 5800xRAM:4x16gb3200mhzGPU: Gigabyte RTX 3090 GAMING OC
ФОТО
Работа на CPU мне не очень интересна, так как на нем заведомо будет медленнее чем на GPU, тем более что видеопамяти нам потребуется немного, в умеренных вариантах ~3gb.
Тестовый пример
Недавно я выпустил видео про запуск gpt-oss-120b. Воспользуемся ffmpeg чтобы вытащить оттуда аудио-поток и используем его в качестве примера для дальнейшей работы:
ffmpeg -i video.mp4 -vn -ac 1 -c:a pcm_s16le -ar 16000 -af "silenceremove=stop_periods=-1:stop_duration=1:stop_threshold=-45dB" audio.wav
Здесь:
- на вход
-iподаемvideo.mp4 - указываем
-ac 1чтобы засунуть весь поток в 1 канал - нам нужны сырые данные
-c:a pcm_s16le(wav) с частотой-ar 16000 - при помощи строки с
-afуказываем: все что ниже-45dBдлительностью 1секstop_duration=1вырезается чтобы у нас не было долгой тишины, иначе могут быть проблемы при транскрибации - выводим в файл
audio.wav
Вы можете столкнуться с проблемой когда модель транскрибирует данные только до определенного места в аудио-файле. Если в файле есть длительный участок тишины, то модель может воспринять это как триггер для окончания обработки файла и закончить.
Чтобы этого не было, нужно вырезать длинные участки тишины, поэтому в прошлой команде вырезается вся тишина длительностью более 1 секунды.
А вот так можно узнать участки тишины (менее -20dB с продолжительностью 1сек) в аудио-файле:
ffmpeg -i audio.wav -af silencedetect=noise=-20dB:d=10 -f null -
Whisper от OpenAI
Whisper — это опенсорсная модель автоматического распознавания речи (ASR), разработанная компанией OpenAI в 2022 году.
Она обучена на 680 000 часов аудио‑текстовых пар, охватывающих более 90 языков и разнообразные акустические условия, что позволяет ей эффективно справляться как с чистой дикторской речью, так и с шумными записками, телефонными разговорами и диалогами в реальном времени. Есть функции обнаружения языка, разметки временных меток и пунктуации.
В оригинальной модели нет диаризации и
TTS, только транскрибация.
Релизы вариантов модели можно посмотреть на HuggingFace.
| Size | Parameters |
|---|---|
| tiny | 39 M |
| base | 74 M |
| small | 244 M |
| medium | 769 M |
| large | 1550 M |
| turbo | 809 M |
У модели large есть несколько вариаций (large, large-v2, large-v3), а модель turbo только large-v3-turbo. Все модели поддерживают многоязычность, однако те файлы моделей, где есть постфикс .en поддерживают только английский язык.
Дальше мы будем тестировать все только на large-v3-turbo как на одной из лучших по качеству и скорости моделей.
Попробуем поработать с оригинальной моделью в точности как указано в репозитории. Установка:
python -m venv .venv
source .venv/bin/activate
pip install openai-whisper
Теперь можем получить справку:
whisper --help
Попробуем транскрибировать тестовый файл:
whisper --model large-v3-turbo --device cuda --language ru audio-sample.wav
Файл модели скачивается автоматически.
Здесь опции:
--model large-v3-turbo: указываем модель, если ее еще нет то она будет скачана--device cuda: указываем бэкэнд, в данном случае CUDA, так как все тесты были на RTX 3090--language ru: язык русский
Результаты транскрибации будут выведены в лог:

Так же в директории будут файлы с разными расширениями где внутри будет транскрибированный текст:
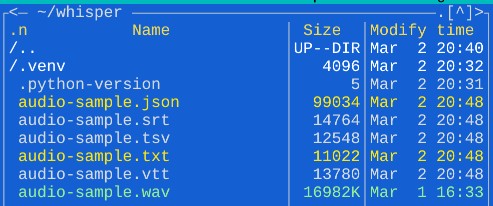
whisper.cpp
whisper.cpp - это высокопроизводительная и автономная реализация инференса оригинального Whisper на C++, с поддержкой разных бэкэндов (CPU, CUDA, Vulkan, OpenVINO и прочее). На Hugging Face список моделей
whisper.cpp поддерживает несколько платформ, может работать через
CLI, а можно запуститьweb-серверс эндпоинтом дляSTT, к тому же в режиме сервера есть web-страница с формой для отправки айдио-файла на транскрибацию.

TTSнет. Есть диаризация, но ее качество сомнительно, потому что не умеет определять спикера и его реплики.
Для того чтобы быстро пощупать мы попробуем запустить Docker-контейнер в режиме сервера.
Загружать модели можно через консольные команды, но я предпочитаю вручную:
# создаем директорию для моделей и переходим в нее
mkdir models
cd model
# скачиваем модель
wget https://huggingface.co/ggerganov/whisper.cpp/resolve/main/ggml-large-v3-turbo-q8_0.bin
Запускаю whisper.cpp так (сразу привожу рабочий вариант, а потом детали):
docker run -it --rm \
-p "8080:8080" \
--gpus all -e LD_LIBRARY_PATH="" \
-v ./models:/models \
ghcr.io/ggml-org/whisper.cpp:main-cuda \
"whisper-server -m /models/ggml-large-v3-turbo-q8_0.bin --host 0.0.0.0 --port 8080 -l ru --print-colors --print-realtime --print-progress --inference-path /audio/transcriptions"
А теперь детали:
LD_LIBRARY_PATH: иначе не получится запустить на GPU-l ru: установка русского языка аудио--print-colors: в логах выводить цвет слов, означающий вероятность совпадения (красный - менее подходящие, зеленый - наиболее подходящий)--print-realtime: выводить логи в реальном времени--print-progress: показывать прогресс обработки--inference-path /audio/transcriptions: переопределение эндпоинта для транскрибации аудио, чтобы можно было встроить в OpenWebUI
--print-* опции удобно использовать для наблюдаемости процесса через логи Docker-контейнера.

Faster Whisper
Стоит немного упомянуть SYSTRAN/faster-whisper хотя бы потому что на нем основаны некоторые другие реализации, которые мы рассмотрим ниже.
faster-whisper это более быстрая реализация OpenAI Whisper на основе движка инференса OpenNMT/CTranslate2, что позволяет faster-whisper быть в несколько раз быстрее (пруфы в репозитории) оригинального Whisper и быстрее whisper.cpp.
Использование Faster Whisper напрямую сейчас мы не будем рассматривать, а перейдем сразу к WhisperX, как одной из наиболее интересных решений использующих Faster Whisper.
WhisperX
WhisperX это расширенная система для распознавания речи на базе Whisper от OpenAI с использованием реализации Faster Whisper. Поддерживает STT в классическом варианте и с диаризацией, TTS нет. В этом проекте только консольный клиент.
Установка:
python -m venv .venv
source .venv/bin/activate
pip install whisperx
Теперь можем посмотреть справку, она достаточно простая:
whisperx --help
Попробуем транскрибировать тестовый файл:
whisperx --model large-v3-turbo --device cuda --device_index 1 --language ru audio-sample.wav
А теперь опции:
--model large-v3-turbo: указываем модель, если ее еще нет то она будет скачана--device cuda: указываем бэкэнд, в данном случае CUDA, так как все тесты были на RTX 3090--device_index 1: мне нужно было именно на второй видеокарте проводить тест--language ru: язык русский
Результаты транскрибации будут выведены в лог и в директории будут файлы:
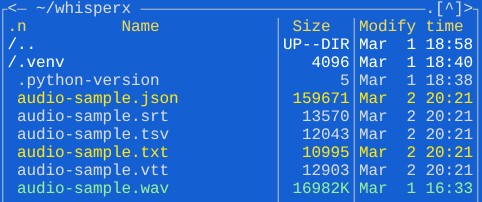
Для использования диаризации потребуется токен от HuggingFace и на странице pyannote/speaker-diarization-community-1 нужно дать согласие.
Вот так можно запустить диаризацию:
whisperx \
--model large-v3-turbo \
--device cuda --device_index 1 \
--language ru \
--diarize --hf_token *** \
audio-sample.wav
whisper-asr-webservice
Whisper ASR Webservice - это обертка в виде API на Python, использует реализации на выбор openai/whisper, SYSTRAN/faster-whisper или whisperX. Однако, по скорости работы это оказался самый спорный проект, либо я как-то не так тестировал. Детали в самом конце.
Имеет документацию, поддерживает STT и диаризацию если выбран движок WhisperX, TTS не поддерживается. Запускается в Docker:
docker run -d --gpus all -p 9000:9000 \
-e ASR_MODEL=large-v3-turbo \
-e ASR_ENGINE=whisperx \
-v $PWD/cache:/root/.cache \
onerahmet/openai-whisper-asr-webservice:latest-gpu
После развертывания доступна страница OpenAPI, через которую можно отправлять запросы и получать ответы:
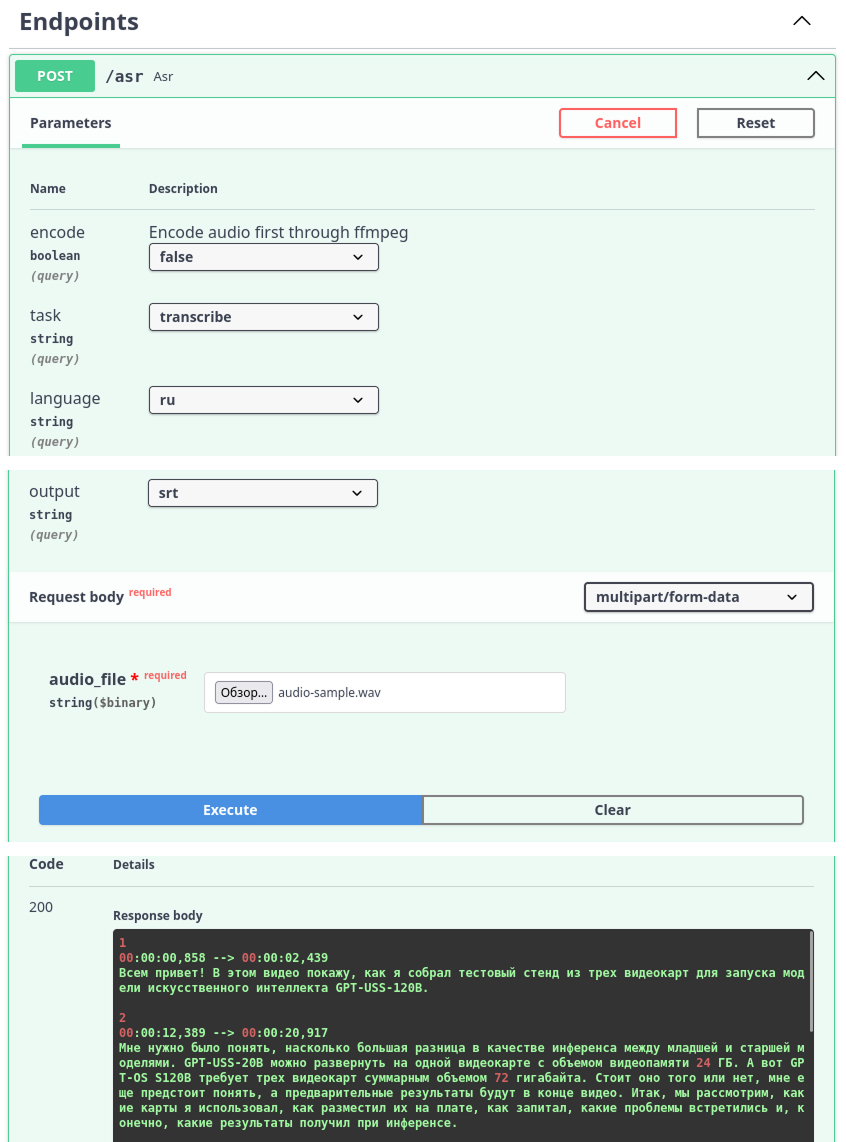
speaches.ai
На репозиторий speaches-ai/speaches я набрел по упоминаниям в интернетах репозитория fedirz/faster-whisper-server, есть даже docker-образ.
Проект идет с web-интерфейсом и поддерживает как STT так и TTS (качество мне не понравилось, к тому же они все картавят), однако скачать выходные файлы нет возможности, что немного печалит. Диаризации нет.
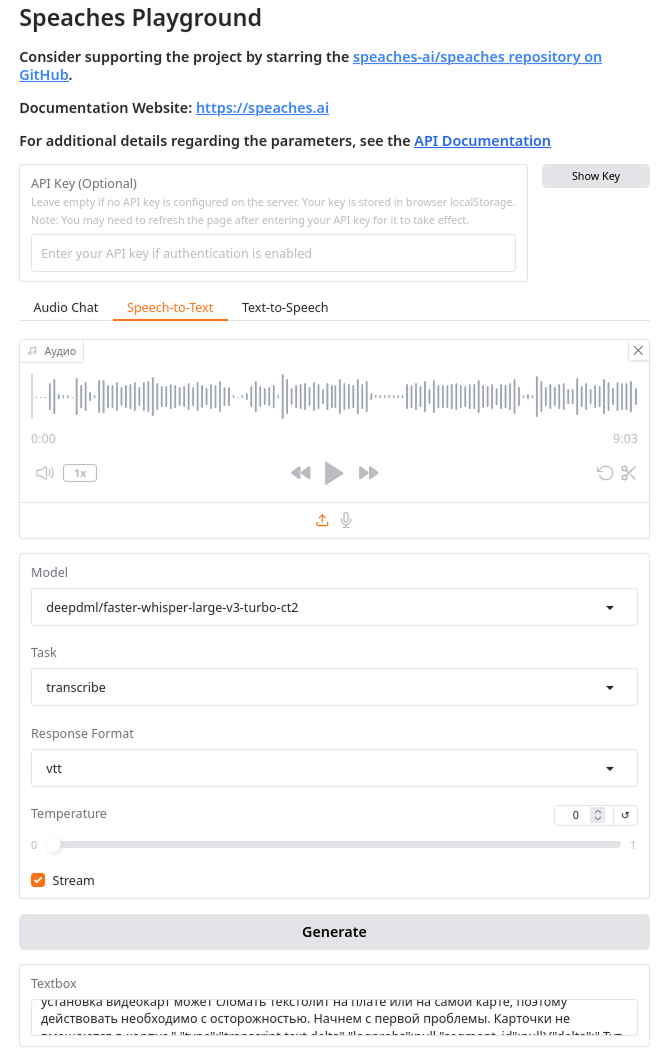
speaches.ai из коробки поддерживает API совместимое с OpenAI, а значит в OpenWebUI можно смело вставлять URL на API.
Документация весьма минималистичная, но исчерпывающая.
Можно запустить в Docker, однако запуск образа по инструкции выдавал ошибку в консоли на web-странице:
Uncaught (in promise) Error: [svelte-i18n] Cannot format a message without first setting the initial locale.
Так как у меня linux/amd64 то я удалил платформу linux/arm64 из compose.yml файла и пересобрал образ:
docker compose --file compose.cuda.yaml build
И теперь после запуска не было ошибок на странице:
docker compose --file compose.cuda.yaml up -d
speaches.ai имеет весьма продуманное API для работы с моделями, и чтобы скачать модель модель придется работать вручную через API:
$SPEACHES_BASE_URL/v1/models: список скачанных моделей$SPEACHES_BASE_URL/v1/registry: список поддерживаемых моделей$SPEACHES_BASE_URL/v1/registry?task=automatic-speech-recognition:список моделей поддерждивающихSTT
А вот так можно скачать конкретную модель из списка:
curl "$SPEACHES_BASE_URL/v1/models/deepdml/faster-whisper-large-v3-turbo-ct2" -X POST
Whisper-WebUI
Репозиторий jhj0517/Whisper-WebUI мне удалось найти по запросу whisper webui в гугл (я еще пользуюсь поисковикамми), а так же есть интересный форк chboishabba/WhisperX-WebUI, который я еще не успел посмотреть.
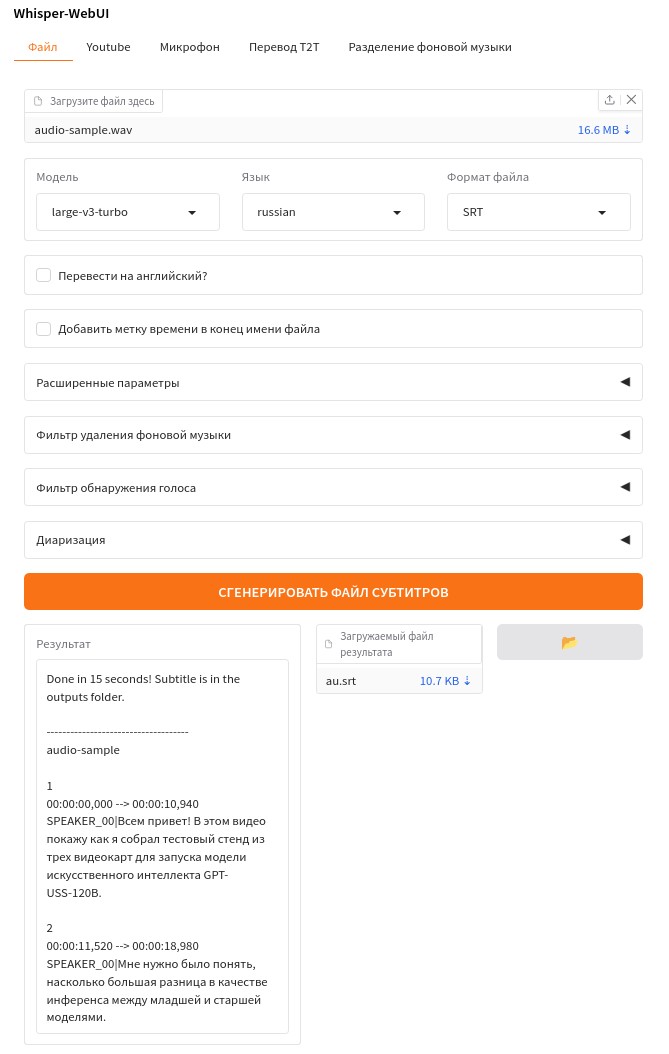
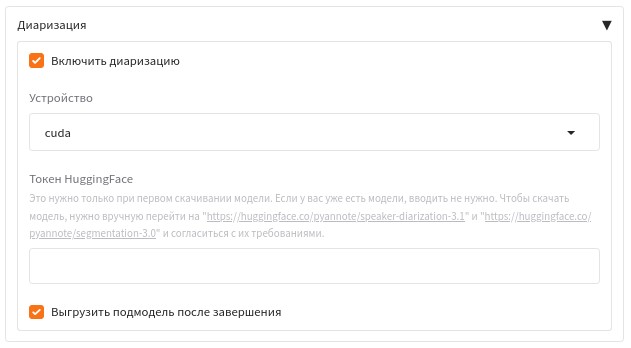
Данный проект я начал использовать раньше чем WhisperX и он меня заинтересовал использованием быстрого SYSTRAN/faster-whisper и поддержкой диаризации через модель pyannote/speaker-diarization-3.1, что должно выдавать совершенно другие результаты по сравнению с whisper.cpp, так и получилось.
При использовании модели диаризации необходимо завести токен на HuggingFace и согласиться с требованиями на странице моделей pyannote/speaker-diarization-3.1 и pyannote/segmentation-3.0.
TTS нет. В отличие от рассмотренного ранее speaches.ai можно скачивать выходные файлы.
Есть возможность запустить в Docker, однако, прежде чем это заработало, мне пришлось внести некоторые правки, а сами образы собираются около 10 минут.
Правки в Dockerfile:
git diff Dockerfile
diff --git a/Dockerfile b/Dockerfile
index 5132d96..ecb29bf 100644
--- a/Dockerfile
+++ b/Dockerfile
@@ -11,7 +11,9 @@ COPY requirements.txt .
RUN python3 -m venv venv && \
. venv/bin/activate && \
- pip install -U -r requirements.txt
+ pip install --upgrade pip && \
+ pip install "setuptools<70" wheel && \
+ pip install --no-build-isolation -r requirements.txt
FROM debian:bookworm-slim AS runtime
Правки в requirements.txt:
git diff requirements.txt
diff --git a/requirements.txt b/requirements.txt
index 386ded4..5f3d91d 100644
--- a/requirements.txt
+++ b/requirements.txt
@@ -10,8 +10,8 @@
# https://download.pytorch.org/whl/xpu
matplotlib
-torch>=2.8.0,<2.9.0 # Needs to be harmonized with torchaudio
-torchaudio>=2.8.0,<2.9.0 # 2.9 deprecates used functions
+#torch>=2.8.0,<2.9.0 # Needs to be harmonized with torchaudio
+#torchaudio>=2.8.0,<2.9.0 # 2.9 deprecates used functions
git+https://github.com/jhj0517/jhj0517-whisper.git
faster-whisper==1.1.1
transformers==4.47.1
@@ -19,6 +19,11 @@ gradio==5.29.0
gradio-i18n==0.3.1
pytubefix
ruamel.yaml==0.18.6
-pyannote.audio==3.3.2
+#pyannote.audio==3.3.2
git+https://github.com/jhj0517/ultimatevocalremover_api.git
git+https://github.com/jhj0517/pyrubberband.git
+
+torch==2.4.1
+torchaudio==2.4.1
+pyannote.audio==3.1.1
+numpy==1.26.4
Другие проекты
Есть еще проекты, которые я не успел посмотреть, оставлю на них ссылки здесь:
Итоги
В ходе обзора каждого проекта я провел тестирование, а теперь подведу сводную таблицу:
| Проект | Длительность STT (сек) | VRAM (gb) | Web | CLI | API OpenAI | TTS | Диаризация |
|---|---|---|---|---|---|---|---|
| openai/whisper | 20* | 6 | ❌ | ✅ | ❌ | ❌ | ❌ |
| whisper.cpp | 4 | 1.3 | ✅ | ✅ | ✅ | ❌ | ✅** |
| WhisperX | 4* | 4.3 | ✅ | ✅ | ✅ | ❌ | ✅ |
| ahmetoner/whisper-asr-webservice | 10 | 5.3 | ✅ | ❌ | ❌ | ❌ | ✅** |
| speaches.ai | 4 | 2.7 | ✅ | ✅ | ✅ | ✅ | ✅ |
| jhj0517/Whisper-WebUI | 15 | 2.2 | ✅ | ✅ | ✅ | ✅ | ❌ |
У openai/whisper еще 8сек загрузка. У whisperx длительность всего 24сек, но обработка самого файла и выдача транскрибации в консоль 4сек. А у ahmetoner/whisper-asr-webservice самые противоречивые показатели (хотя скорости должны быть другими):
openai-whisper: 10секfaster-whisper: 12секwhisperx: 18сек
Диаризация у whisper.cpp и ahmetoner/whisper-asr-webservice мне не понравилась, нет точности, разделение по спикерам хаотичное.
Хотя сейчас у меня на сервере развернуты все проекты, но больше всего мне понравился проект jhj0517/Whisper-WebUI. Несмотря на то что он медленнее обрабатывает файлы, у него есть качественная диаризация и потребляет относительно немного VRAM.
Если нужно все то же самое, но в терминале то WhisperX вполне подходит.
Если нужна только транскрибация то whisper.cpp самое подходящее решение: прост в использовании и занимает мало видеопамяти.