Запуск gpt-oss-120b на трех видеокартах
Несколько месяцев назад так случилось что у меня появилась третья видеокарта, а общий объем видеопамяти составил 72гб. После длительных тестов gpt-oss-20b мне захотелось получать более разумные ответы и я решил собрать тестовый стенд для тестирования старшей модели gpt-oss-120b из того оборудования, что у меня было. Результат того стоил.

Видеокарты
Моя первая карта Tesla P40 с кастомной системой охлаждения, на которой я проводил первые длительные тесты ИИ в работе. Эта карта потребляет всего 250 Вт, в комплекте шел кабель переходник 2 PCI-коннектора на CPU, оказывается Tesla имеет разъем питания CPU. В ширину занимает 2 PCI-слота.


После этого приобрел RTX 3090 TI от KFA2, разъем питания 12+4 pin с переходником на 3 PCI-коннектора, стоковое потребление 450 Вт, но на практике не более 360, а максимальное 480. В ширину занимает чуть больше чем 3 PCI-слота.

Затем купил Asus Rog String RTX 3090 с тремя PCI-разъемами. Стоковое потребление 390 Вт, а максимальное 480, и она действительно может столько потреблять. В ширину занимает 3 PCI-слота.

Итого: нужно 8
PCI-слотовв ширину.
Материнская плата
В качестве стенда для размещения я взял свой домашний сервер с материнской платой Huananzhi F8D Plus, которая оснащена 6-ю слотами PCIE.

Эта плата была размещена в корпусе XPG Defender, в который можно разместить видеокарты шириной максимум на 6 PCI-слотов. А мне нужно на 8! Чуть позже мы решим эту проблему.

В корпус не влезут все 3 карты, поэтому я разобрал сервер и втащил из него материнскую плату, чтобы вставить карты в следующем порядке:
Tesla P40: в самый верхний слот, она занимает всего 2PCI-слотав ширинуAsus Rog Strix RTX 3090: затем в третий слот, эта карта занимает ровно 3PCI-слота*RTX 3090 TI от KFA2: и наконец в шестой слот, которая в ширину больше чем 3PCI-слота
Каждую карту нужно подпереть для устойчивости, чтобы не было заломов и провисаний, иначе текстолит или сам слот могут сломаться.
Блок питания
У меня уже был блок питания Azerty Red Power на 1050 Вт от моего домашнего сервера, он оснащен тремя раздвоенными PCI-кабелями (6 коннекторов) и двумя кабелями питания CPU.

Но карты требуют 8 PCI-разъемов, а у меня в наличии только 6. Тем более, что запитать нужно обязательно все разъемы, иначе карты не стартуют.
Вспоминаем что Tesla P40 имеет CPU-разъем питания, а мой БП как раз содержит раздвоенные кабели питания CPU, подключив удлинитель к одному из свободных кабелей удалось запитать карту.
Можно подумать что одним кабелем можно запитать аж 2 PCI-разъема, ведь один кабель имеет два выходных коннектора питания.

Но как показала практика это заблуждение, потому что карте может не хватить питания из-за ограниченной пропускной способности проводов. Как итог: отвал карты и необходимость перезагружать систему. Некритично, но мало приятного, особенно на постоянной основе.
Каждый 8‑pin
PCIe‑кабельспособен передать до150W, если карта имеет 3 разъёма, её суммарная мощность может достигать450W.
А вас не смутило что я пытаюсь запитать видеокарты общей мощностью 1210 Вт от блока питания на 1050 Вт?
Tesla P40 будет самым слабым звеном в этой вычислительной цепи и не даст расрктыться всей мощи RTX 3090. А значит, для моего эксперимента допустимо запитать одним кабелем 2 разъема видеокарты. Позже на практике мы увидим реальный уровень энергопотребления.
Запуск моделей
Подсоединив все кабели питания можно пробовать включать.
Установил 580-й драйвер от NVIDIA на Debian 12, скачал модели gpt-oss-20b и gpt-oss-120b и запустил модели в llamacpp через docker-контейнеры.
Обе модели будем распределять на все 3 видеокарты, чтобы понять как можно использовать несколько видеокарт.
При генерации ответа модель выдает ~100 токенов/с на gpt-oss-20b и ~70 токенов/с на модели gpt-oss-120b при генерации ответа.
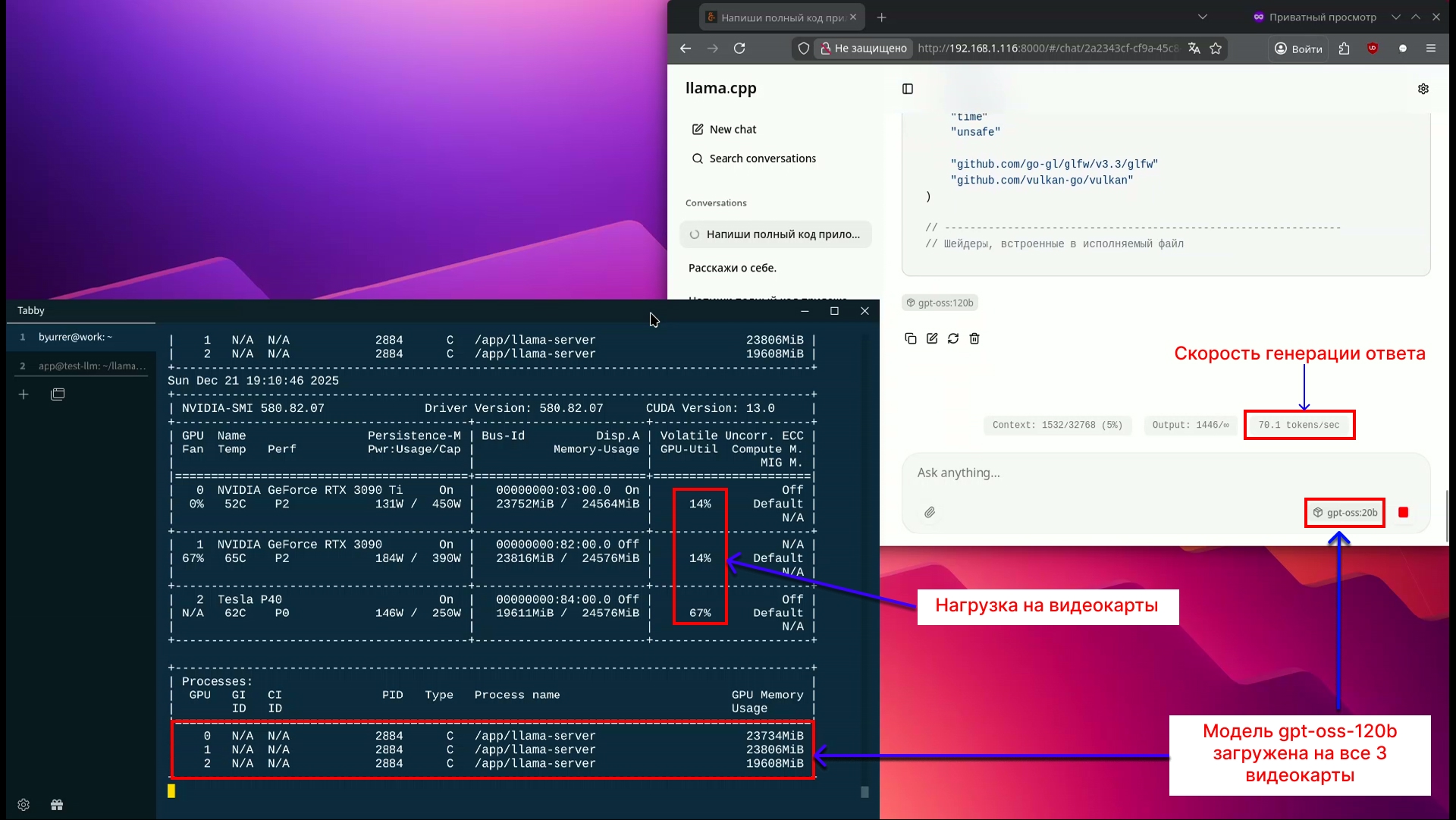
При этом нагрузка на видеокарты RTX 3090 примерно 16%, а напряжение на уровне 150-180 Вт. Почему не полная нагрузка на RTX 3090?
Tesla P40слабое звено в этой вычислительной цепи и не дает раскрыться всей мощиRTX 3090.
Впечатления
Во время инференса вся эта установка потребляет около 630 Вт. Опять же Tesla P40 не дает раскрыться мощи остальных видеокарт. Шум вполне терпим. А вот вентиляции этой открытой установки почти нет, но для данной ситуации этого не и требовалось.

После эксперимента я тестировал gpt-oss-120b на открытой сборке еще несколько дней, в том числе в рабочих задачах, в ходе тестов модель показала себя значительно лучше, чем младшая версия gpt-oss-20b и была на уровне близком к ChatGPT 4.1, а с этой моделью я провел достаточно много работы решая задачи.
Как вы уже наверное догадались: меня вполне устроили результаты и я продолжил развивать эту сборку. Я перевез видеокарты в корпус и на плату для майнинга, так как именно такие платы располагают большим количеством и пространством между PCI-слотами.
